
My(Your)SQL

My(Your)SQL
Kitholt FrankMy(Your)SQL
数据类型
数值
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 字节 | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 字节 | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 字节 | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 字节 | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 字节 | (-9 233 372 036 854 775 808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 字节 | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 字节 | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
日期
| 类型 | 大小 (字节) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038-1-19 03:14:07 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
字符串
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255字节 | 定长字符串 |
| VARCHAR | 0-65535 字节 | 变长字符串 |
| TINYBLOB | 0-255字节 | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255字节 | 短文本字符串 |
| BLOB | 0-65 535字节 | 二进制形式的长文本数据 |
| TEXT | 0-65 535字节 | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215字节 | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295字节 | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295字节 | 极大文本数据 |
CHAR 和 VARCHAR:
CHAR在定义时会限定存储空间大小,比如一开始规定5个字符。后续如果只给定2个字符,CHAR会自动用空格补齐。
CHAR浪费存储空间,但效率高,VARCHAR则反之
使用数据库的基(只因)本语法
数据库、表(增删改查)略
- 插入:insert into…values
- 更新:update…set column_name = …
- 删除(不完全删除):delete from…[where…]
- 删除(完全删除):truncate…
with rollup
WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)
MySQL 连接的使用
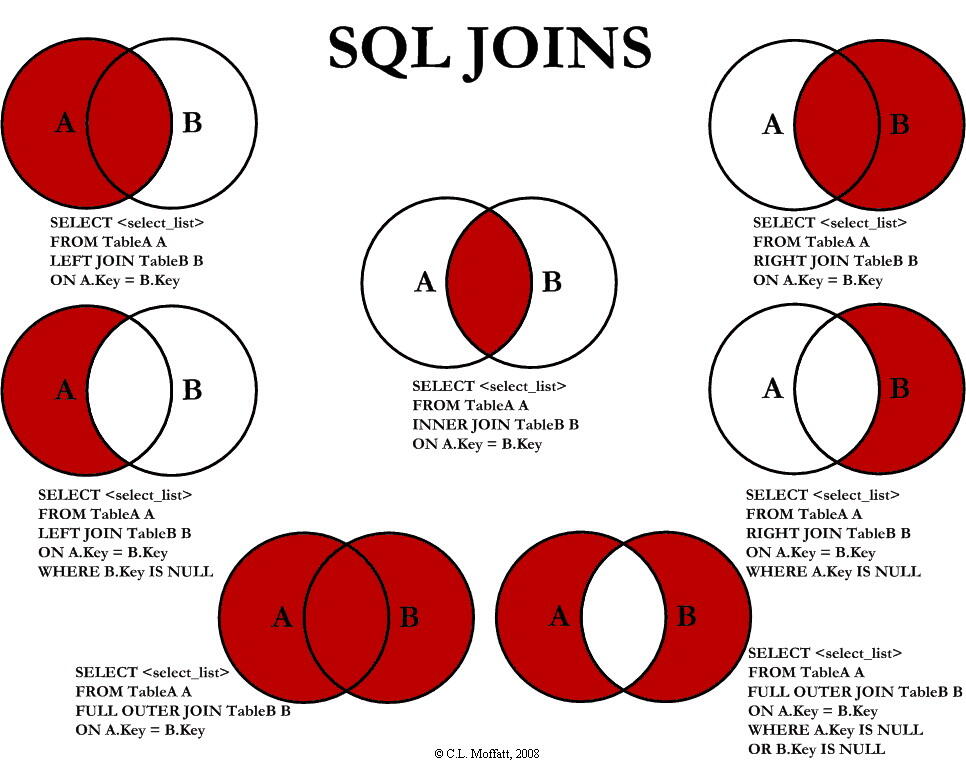
外连接:
- 左外连接【left join】两表连接,返回满足连接条件的行,并且返回左表中不满足的条件的行
- 右外连接【right join】
- 满外连接【full outer join】
事务—多条数据操作语句构成的集合
A(原子性—要么完成要么撤回,如果出错会回滚到事务开始前的状态
C(一致性—事务开始和结束后,数据库的完整性都没被破坏(前后数据不会矛盾
I(隔离性—允许多个事务并发执行,对数据进行读写修改
D(持久性—事务处理结束后对数据的修改是永久的
存储过程(stored procedure
一组经过预先编译的SQL语句的封装
优:
- 简化操作,提高重用性
- 减少网络传输量(因为语句都保存在MySQL服务器上
- 提高查询安全性,客户端只需要发送查询请求
存储引擎innoDB
索引
用于快速查找数据记录的数据结构
优
- 减少磁盘io次数,加快查询效率
- 加快表与表之间的连接
- 减少分组和排序的时间
劣
- 创建索引和维护需要时间
- 会降低表的更新速度(因为每次进行数据操作时,除了更新数据,还要更新索引)
一个简单的索引结构
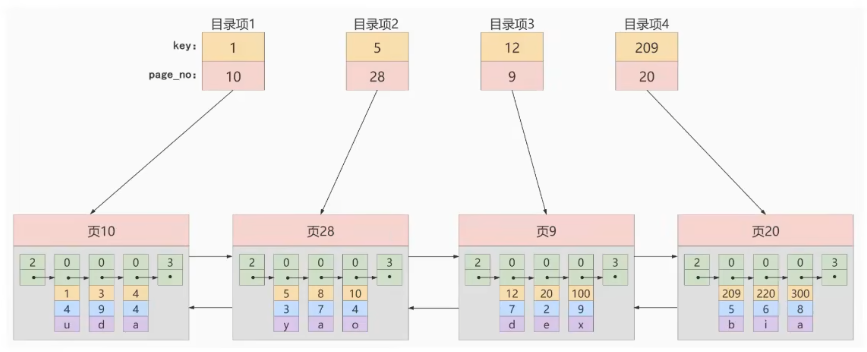
B+树 = 数据页(叶子节点) + 目录页(内节点)
- B+树层数一般不超过4
- B+树层数越少,IO次数越少
索引分类
聚簇索引
也叫簇类索引,是一种对磁盘上实际数据重新组织以按指定的一个或多个列的值排序。由于聚簇索引的索引页面指针指向数据页面,所以使用聚簇索引查找数据几乎总是比使用非聚簇索引快。一张表只能有一个聚簇索引,一般由主键构成
索引即数据,数据即索引
叶子节点存储了全部数据列
二级索引(非聚簇索引)
叶子节点存储了【一个主键以外的列+主键值】,因此使用二级索引查找数据时,最后会进行回表操作(再通过主键值进行一次聚簇索引查找
联合索引
叶子节点存储了【多个主键以外的列+主键值】
关于索引的操作
- create [索引类型] [索引名称] on [表名] (列名)
- drop index [索引名称] on [表名]
视图
视图(View)是一个基于 SQL 查询创建的虚拟表,它不存储数据,而是每次访问时动态地从基础表中提取最新数据。这样设计的目的是为了避免数据冗余,确保数据一致性,并简化复杂查询。通过视图,你可以方便地展示和查询数据,同时隐藏底层的复杂性和敏感信息。
触发器中的NEW OLD
在数据库触发器中,OLD 和 NEW 是特殊的关键字,用于表示触发事件(如 INSERT、UPDATE、DELETE)中记录的旧值和新值。它们是触发器内部访问数据的核心机制,具体含义如下:
1. OLD 的含义
- 表示记录在触发事件前的原始值。
- 适用场景:
UPDATE操作:记录被修改前的原始值。DELETE操作:记录被删除前的原始值。
- 不可用场景:
INSERT操作(因为插入的是新记录,没有旧值)。
示例(UPDATE 操作):
假设更新前某行的 student_id 是 100,OLD.student_id 会返回 100。
2. NEW 的含义
- 表示触发事件后的新值。
- 适用场景:
INSERT操作:新插入的记录值。UPDATE操作:记录被修改后的新值。
- 不可用场景:
DELETE操作(因为删除后没有新值)。
示例(UPDATE 操作):
假设更新后某行的 student_id 被改为 200,NEW.student_id 会返回 200。
3. OLD 和 NEW 的可用性总结
| 操作类型 | OLD 是否可用 |
NEW 是否可用 |
|---|---|---|
| INSERT | ❌ 不可用 | ✅ 可用 |
| UPDATE | ✅ 可用 | ✅ 可用 |
| DELETE | ✅ 可用 | ❌ 不可用 |
4. 核心作用
- 验证数据:检查
NEW的值是否符合业务逻辑(如外键约束、范围校验)。 - 修改数据:在
BEFORE触发器中,可以直接修改NEW的值(如强制修正非法值)。 - 记录对比:通过
OLD和NEW的差异,实现日志记录或审计功能。
示例场景(修正非法值):
1 | CREATE TRIGGER validate_student |
5. 注意事项
仅限行级触发器:
OLD和NEW仅在FOR EACH ROW的触发器中使用(逐行处理)。- 表级触发器(非逐行)不支持这两个关键字。
OLD是只读的:- 只能读取
OLD的值,不能修改它(例如SET OLD.student_id = 100会报错)。
- 只能读取
NEW可修改:- 在
BEFORE触发器中,可以修改NEW的值,从而改变实际写入数据库的数据。 - 在
AFTER触发器中,NEW不可修改(因为数据已写入)。
- 在
6. 实际应用示例
场景:更新 recording 表时,确保 company_id 有效,否则保留原值。
1 | CREATE TRIGGER validate_company |
效果:
- 如果用户尝试将
company_id更新为一个不存在的值,触发器会自动恢复为原来的值。 - 如果更新合法,则正常写入新值。
Learn from SQLZOOOOOOOOOOO
窗口函数
SQL窗口函数是SQL中的一种高级函数它允许用户在不显式分组查询的情况下对结果集进行分组和聚合计算,窗口函数的特别之处在于,它们将结果集中的每一行看作一个单独的计算对象,而不是将结果集划分为分组并计算每个分组的聚合值这就使得窗口函数能够为结果集中的每一行计算类似排名、行号、百分比和移动聚合函数等值
窗口函数和聚合函数的区别
- 聚集函数通过对数据进行分组,仅能够输出分组汇总结果
- 窗口函数则可以同时将原始数据和聚集分析结果同时显示出来
子查询
相关子查询(❎独立执行)
- 依赖主查询的数据
- 先执行主查询,再执行子查询
非相关子查询(✅独立执行)
- 独立于外部查询的子查询,子查询总共执行一次,执行完毕后将值传递给外部查询
- 执行子查询,其结果不被显示,而是传递给外部查询,作为外部查询的条件使用
CASE WHEN
CASE
CASE allows you to return different values under different conditions.
If there no conditions match (and there is not ELSE) then NULL is returned.
1 | CASE WHEN condition1 THEN value1 |
COALESCE
COALESCE takes any number of arguments and returns the first value that is not null.
1 | COALESCE(x,y,z) = x if x is not NULL |
Replace
replace(column, old value, new value)
1 | update titles_test |
例题
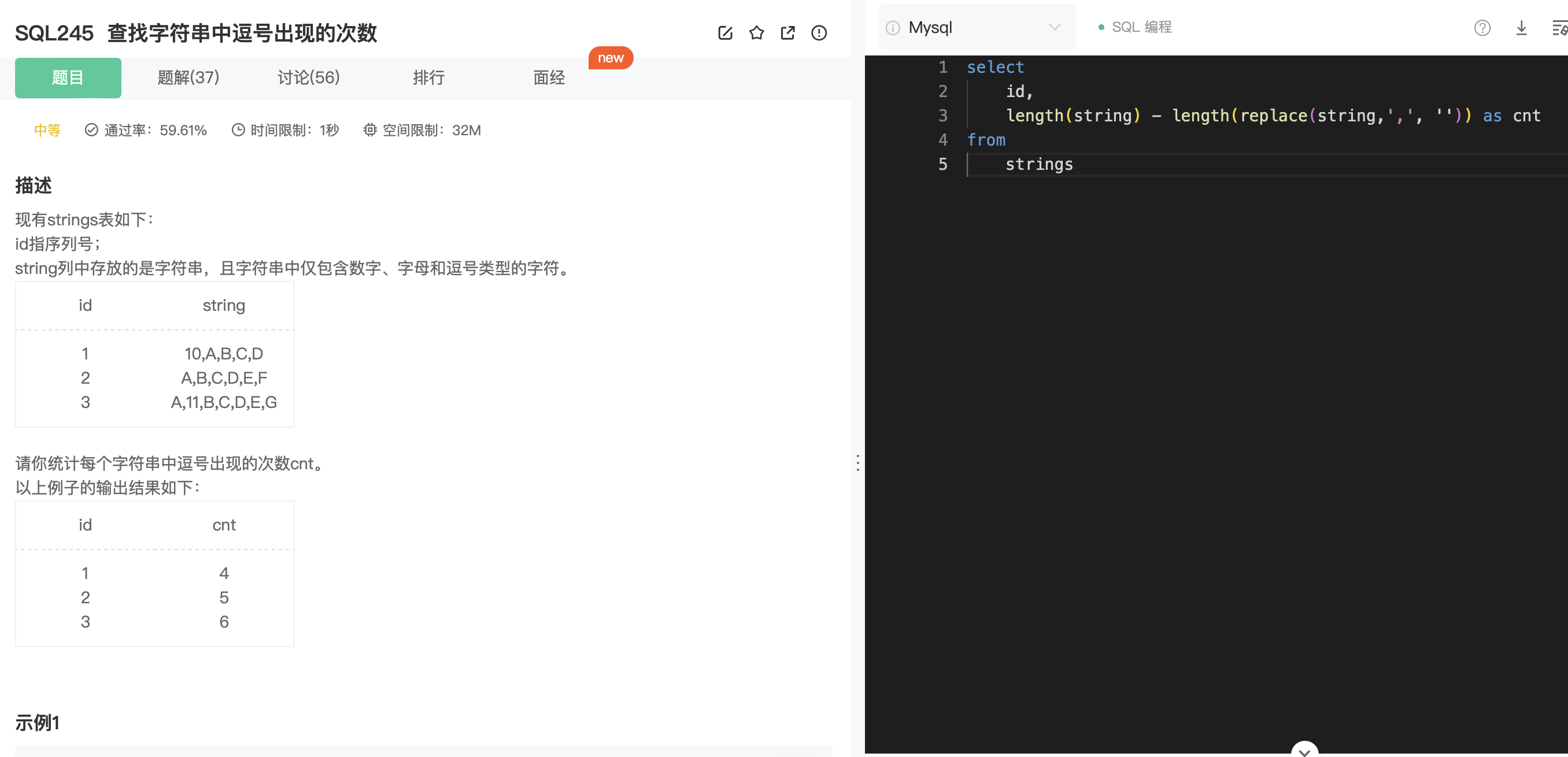
GROUP_CONCAT 函数(MySQL)
功能:
- 将一组结果中的值连接成一个字符串。
基本语法:
1 | SELECT GROUP_CONCAT(column_name SEPARATOR 'separator') |
column_name: 要连接的列。SEPARATOR 'separator': 可选,用于指定分隔符,默认为逗号(,),可以设置为空字符串''。
示例:
1 | SELECT GROUP_CONCAT(name SEPARATOR ', ') AS student_names |
结果:
'Alice, Bob, Charlie'
关键点:
- 连接字符串:将多行结果连接为一个字符串。
- 自定义分隔符:通过
SEPARATOR子句指定连接字符之间的分隔符。 - 与 GROUP BY 结合使用:通常用于分组后的数据连接。
- 长度限制:默认最大长度有限制,可通过调整
group_concat_max_len系统变量修改。
应用场景:
- 生成以逗号分隔的列表(如 CSV)。
- 将多值合并为一个字符串进行显示。
LIMIT和 OFFSET用法总结
1. 只使用 LIMIT
语法:
1 | SELECT column_name(s) |
功能:
- 从结果集的 第一行 开始,返回最多
number_of_rows行数据。
示例:
1 | SELECT * FROM employees LIMIT 5; |
- 结果: 返回前 5 行数据。
2. 同时使用 LIMIT 和 OFFSET
语法:
1 | SELECT column_name(s) |
功能:
- 跳过
offset_value行,然后返回接下来的number_of_rows行数据。
示例:
1 | SELECT * FROM employees LIMIT 5 OFFSET 10; |
结果:
- 跳过前 10 行,返回第 11 行到第 15 行的数据。
应用场景:
- 分页查询:获取某一页的数据,例如第 2 页的内容,每页 10 条记录。
3. MySQL 特有语法 (LIMIT 后两个参数)
语法:
1 | SELECT column_name(s) |
功能:
- 跳过
offset_value行,从第offset_value + 1行开始,返回number_of_rows行数据。
示例:
1 | SELECT * FROM employees LIMIT 5, 12; |
结果:
- 跳过前 5 行,从第 6 行开始,返回接下来的 12 行数据。
应用场景:
- 实现分页或获取特定范围的数据。例如,第 2 页,每页 12 条记录的数据。
总结
- 只使用
LIMIT: 返回从结果集的开头开始的固定数量的行。 LIMIT和OFFSET结合使用: 从结果集中的某个位置开始返回指定数量的行,适用于分页查询。- MySQL 特有语法: 通过两个参数实现跳过一定行数并返回接下来的行。
DATE_ADD
功能:
- 向日期或时间值添加指定的时间间隔。
基本语法:
1 | DATE_ADD(date, INTERVAL value unit) |
- date: 需要操作的日期或时间值。
- INTERVAL value unit: 要添加的时间间隔。
value: 间隔的数量(整数)。unit: 时间单位(如 DAY、MONTH、YEAR、HOUR 等)。
示例:
添加天数:
1
SELECT DATE_ADD(date_column, INTERVAL 5 DAY) AS new_date FROM table_name;
添加月份:
1
SELECT DATE_ADD(date_column, INTERVAL 2 MONTH) AS new_date FROM table_name;
添加小时:
1
SELECT DATE_ADD(date_column, INTERVAL 3 HOUR) AS new_date FROM table_name;
DATE_FORMAT 函数
用途: 将日期格式化为指定的==字符串==格式。
语法:
1 | DATE_FORMAT(date, format) |
• date: 要格式化的日期。
• format: 输出日期的格式,使用格式化符号(如 %Y、%m、%d)。
STR_TO_DATE 函数
用途: 将字符串转换为日期。
语法:
1 | STR_TO_DATE(string, format) |
•string: 要转换的日期字符串。
• format: 字符串的日期格式,使用格式化符号(如 %Y、%m、%d)。
ROW_NUMBER 函数
作用: ROW_NUMBER 是 SQL 中的窗口函数,为查询结果中的每一行生成一个唯一的行号。
基本语法:
1 | SELECT |
常见用途:
- 分页查询: 用行号实现数据分页。
- 去重操作: 对分组结果集排序并选择行号为 1 的数据。
- 排序显示: 为每行数据添加顺序号。
示例:
为学生成绩表生成基于成绩的排名:
1 | SELECT |
结果:
| name | score | rank |
|---|---|---|
| Bob | 92 | 1 |
| Alice | 85 | 2 |
| David | 85 | 3 |
| Charlie | 78 | 4 |
ROWS BETWEEN
1 | 窗口函数() OVER ( |
| 选项 | 说明 |
|---|---|
UNBOUNDED PRECEDING |
窗口从分区的第一行开始。 |
n PRECEDING |
窗口从当前行之前的第 n 行开始(n 是正整数)。 |
CURRENT ROW |
窗口包含当前行。 |
n FOLLOWING |
窗口到当前行之后的第 n 行结束。 |
UNBOUNDED FOLLOWING |
窗口到分区的最后一行结束。 |
SQL题2022(由易到难)
1. 题目:
现在运营需要查看用户来自于哪些学校,请从用户信息表中取出学校的去重数据。
distinct关键字的使用
2. 题目:
现在运营只需要查看前2个用户明细设备ID数据,请你从用户信息表 user_profile 中取出相应结果。
limit关键字的使用
3. 题目:
现在你需要查看前2个用户明细设备ID数据,并将列名改为 ‘user_infos_example’,,请你从用户信息表取出相应结果。
as关键字的使用
4. 题目:
现在运营想要取出用户信息表中对应的数据,并先按照gpa、年龄降(升)序排序输出,请取出相应数据。
asc和desc的使用
5. 题目:
现在运营想要对用户的年龄分布开展分析,在分析时想要剔除没有获取到年龄的用户,请你取出所有年龄值不为空的用户的设备ID,性别,年龄,学校的信息。
where过滤空值,使用is来判断是否为空
6. 题目:
现在运营想要对每个学校不同性别的用户活跃情况和发帖数量进行分析,请分别计算出每个学校每种性别的用户数、30天内平均活跃天数和平均发帖数量。**
| id | device_id | gender | age | university | gpa | active_days_within_30 | question_cnt | answer_cnt |
|---|---|---|---|---|---|---|---|---|
| 1 | 2138 | male | 21 | 北京大学 | 3.4 | 7 | 2 | 12 |
| 2 | 3214 | male | 复旦大学 | 4.0 | 15 | 5 | 25 | |
| 3 | 6543 | female | 20 | 北京大学 | 3.2 | 12 | 3 | 30 |
| 4 | 2315 | female | 23 | 浙江大学 | 3.6 | 5 | 1 | 2 |
| 5 | 5432 | male | 25 | 山东大学 | 3.8 | 20 | 15 | 70 |
| 6 | 2131 | male | 28 | 山东大学 | 3.3 | 15 | 7 | 13 |
| 7 | 4321 | male | 26 | 复旦大学 | 3.6 | 9 | 6 | 52 |
1 | select |
7. 题目:
现在运营想查看每个学校用户的平均发贴和回帖情况,寻找低活跃度学校进行重点运营,请取出平均发贴数低于5的学校或平均回帖数小于20的学校。
1 | select |
我的错误点:一开始使用了where
university having
使用HAVING
HAVING子句用于对分组后的结果再进行过滤,
它的功能有点像WHERE子句,但它用于组而不是单个记录。
在HAVING子句中可以使用统计函数,但在WHERE子句中则不能。
HAVING通常与GROUP BY子句一起使用。
8. 题目:
运营想要计算一些参加了答题的不同学校、不同难度的用户平均答题量,请你写SQL取出相应数据
用户信息表:user_profile
| id | device_id | gender | age | university | gpa | active_days_within_30 | question_cnt | answer_cnt |
|---|---|---|---|---|---|---|---|---|
| 1 | 2138 | male | 21 | 北京大学 | 3.4 | 7 | 2 | 12 |
| 2 | 3214 | male | NULL | 复旦大学 | 4 | 15 | 5 | 25 |
| 3 | 6543 | female | 20 | 北京大学 | 3.2 | 12 | 3 | 30 |
| 4 | 2315 | female | 23 | 浙江大学 | 3.6 | 5 | 1 | 2 |
| 5 | 5432 | male | 25 | 山东大学 | 3.8 | 20 | 15 | 70 |
| 6 | 2131 | male | 28 | 山东大学 | 3.3 | 15 | 7 | 13 |
| 7 | 4321 | male | 28 | 复旦大学 | 3.6 | 9 | 6 | 52 |
题库练习明细表:question_practice_detail
| id | device_id | question_id | result |
|---|---|---|---|
| 1 | 2138 | 111 | wrong |
| 2 | 3214 | 112 | wrong |
| 3 | 3214 | 113 | wrong |
| 4 | 6534 | 111 | right |
| 5 | 2315 | 115 | right |
| 6 | 2315 | 116 | right |
| 7 | 2315 | 117 | wrong |
| 8 | 5432 | 117 | wrong |
| 9 | 5432 | 112 | wrong |
| 10 | 2131 | 113 | right |
| 11 | 5432 | 113 | wrong |
| 12 | 2315 | 115 | right |
| 13 | 2315 | 116 | right |
| 14 | 2315 | 117 | wrong |
| 15 | 5432 | 117 | wrong |
| 16 | 5432 | 112 | wrong |
| 17 | 2131 | 113 | right |
| 18 | 5432 | 113 | wrong |
| 19 | 2315 | 117 | wrong |
| 20 | 5432 | 117 | wrong |
| 21 | 5432 | 112 | wrong |
| 22 | 2131 | 113 | right |
| 23 | 5432 | 113 | wrong |
问题细节表:question_detail
| id | question_id | difficult_level |
|---|---|---|
| 1 | 111 | hard |
| 2 | 112 | medium |
| 3 | 113 | easy |
| 4 | 115 | easy |
| 5 | 116 | medium |
| 6 | 117 | easy |
应该返回的结果:
| university | difficult_level | avg_answer_cnt |
|---|---|---|
| 北京大学 | hard | 1.0000 |
| 复旦大学 | easy | 1.0000 |
| 复旦大学 | medium | 1.0000 |
| 山东大学 | easy | 4.5000 |
| 山东大学 | medium | 3.0000 |
| 浙江大学 | easy | 5.0000 |
| 浙江大学 | medium | 2.0000 |
1 | select |
9. 题目:
运营想要查看参加了答题的山东大学的用户在不同难度下的平均答题题目数,请取出相应数据
- 山东大学的用户
- 不同难度
- 平均答题题目数
1 | select |
10. 题目:
现在运营想要分别查看学校为山东大学或者性别为男性的用户的device_id、gender、age和gpa数据,请取出相应结果,结果不去重。
结果不去重,需要使用到union all
union 和union all的区别
union是合并两个查询语句的结果集,并排除重复项
union all是不排除重复项的,(符合题目要求)
- union使用前提
- 使用union合并两个表时,需要两个表的结果集字段完全一样;
- 表一(SELECT device_id,gender,age,gpa );
- 表二(SELECT device_id,gender,age,gpa)
11. 题目:
现在运营想要查看用户在某天刷题后第二天还会再来刷题的平均概率。请你取出相应数据。
| id | device_id | quest_id | result | date |
|---|---|---|---|---|
| 1 | 2138 | 111 | wrong | 2021-05-03 |
| 2 | 3214 | 112 | wrong | 2021-05-09 |
| 3 | 3214 | 113 | wrong | 2021-06-15 |
| 4 | 6543 | 111 | right | 2021-08-13 |
| 5 | 2315 | 115 | right | 2021-08-13 |
| 6 | 2315 | 116 | right | 2021-08-14 |
| 7 | 2315 | 117 | wrong | 2021-08-15 |
思路:
原表a,复制一份表b
先去重(有可能一个用户一天刷多次题
表b的时间全部+1(day
- 需要使用的方法——date_add(date,interval 1 day)
如果第二天还会来刷题,那么两个表左外连接的结果就是:连续两天刷题的行数据没有null值出现
某天刷题后第二天还会再来刷题的平均概率:统计非null的行/所有行
1 | select avg(if(b.device_id is not null,1,0)) as avg_ret |
12. 题目:
现在运营举办了一场比赛,收到了一些参赛申请,表数据记录形式如下所示,现在运营想要统计每个性别的用户分别有多少参赛者,请取出相应结果
| device_id | profile | blog_url |
|---|---|---|
| 2138 | 180cm,75kg,27,male | http:/url/bigboy777 |
| 3214 | 165cm,45kg,26,female | http:/url/kittycc |
| 6543 | 178cm,65kg,25,male | http:/url/tiger |
| 4321 | 171cm,55kg,23,female | http:/url/uhksd |
| 2131 | 168cm,45kg,22,female | http:/urlsydney |
观察:
很明显profile字段的存储类型是字符串,里面有多条信息。需要用到某些函数来实现字符串的分割
函数:
substring_index(str, delim, count)
- str:要处理的字符串
- delim:分隔符
- count:计数
- 如果count为正数n,就从左往右数,截取第n个分隔符的左边全部内容,n为负数的话,则反之
1 | select |
13.题目:
现在运营想要找到每个学校gpa最低的同学来做调研,请你取出每个学校的最低gpa。
1 | select |
以上是错误的语句,此时得到的结果中,最低的gpa对应的device_id有可能不一致
解决方法:
- 先根据原表(表a)拿到每个学校最低的gpa(表b
- ab两表 内连接
1 | select |
14.题目:
现在运营想要了解复旦大学的每个用户在8月份练习的总题目数和回答正确的题目数情况,请取出相应明细数据,对于在8月份没有练习过的用户,答题数结果返回0.
分析:
- 学校限制:复旦大学—‘复旦大学’ as university
- 八月份的练习—month(b.date) = 8
- 8月份没有练习过的用户,答题数结果返回0—左连接
- 8月份练习的总题目数—count(b.question_id) as question_cnt
- 回答正确的题目数—sum(if(b.result = ‘right’, 1, 0)) as right_question_cnt
1 | select |
15.题目:
现在运营想要了解浙江大学的用户在不同难度题目下答题的正确率情况,请取出相应数据,并按照准确率升序输出。
分析:
- 答题正确率
- 不同难度下的题目
- 浙江大学
- 准确率升序输出
1 | select |
16.题目:
现有一张试卷作答记录表exam_record,其中包含多年来的用户作答试卷记录,结构如下表:
作答记录表exam_record:
start_time是试卷开始时间
submit_time 是交卷,即结束时间
| Filed | Type | Null | Key | Extra | Default | Comment |
|---|---|---|---|---|---|---|
| id | int(11) | NO | PRI | auto_increment | (NULL) | 自增ID |
| uid | int(11) | NO | (NULL) | 用户ID | ||
| exam_id | int(11) | NO | (NULL) | 试卷ID | ||
| start_time | datetime | NO | (NULL) | 开始时间 | ||
| submit_time | datetime | YES | (NULL) | 提交时间 | ||
| score | tinyint(4) | YES | (NULL) | 得分 |
请删除exam_record表中作答时间小于5分钟整且分数不及格(及格线为60分)的记录
分析:
计算时间差,需要用到的函数
- TIMESTAMPDIFF(interval, time_start, time_end)可计算time_start-time_end的时间差,单位以指定的interval为准,常用可选:
- SECOND 秒
- MINUTE 分钟(返回秒数差除以60的整数部分)
- HOUR 小时(返回秒数差除以3600的整数部分)
- DAY 天数(返回秒数差除以3600*24的整数部分)
- MONTH 月数
- YEAR 年数
1 | delete from |
17.题目:
牛客的运营同学想要查看大家在SQL类别中高难度试卷的得分情况。
请你帮她从exam_record数据表中计算所有用户完成SQL类别高难度试卷得分的截断平均值(去掉一个最大值和一个最小值后的平均值)。
示例数据:examination_info(exam_id试卷ID, tag试卷类别, difficulty试卷难度, duration考试时长, release_time发布时间)
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
| 2 | 9002 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
| 3 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:31:01 | 84 |
| 4 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
| 5 | 1001 | 9001 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 7 | 1002 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
| 8 | 1002 | 9001 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
| 9 | 1003 | 9001 | 2021-09-07 12:01:01 | 2021-09-07 10:31:01 | 50 |
| 10 | 1004 | 9001 | 2021-09-06 10:01:01 | (NULL) | (NULL) |
分析:
- SQL类别—where
- 高难度—where
- 截断平均值— round((sum(score) - max(score) - min(score)) / (count(score) - 2),1)
1 | select |
18.题目:
请从试卷作答记录表中找到SQL试卷得分不小于该类试卷平均得分的用户最低得分。
示例数据 exam_record表(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 5 | 1002 | 9001 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
| 6 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
| 7 | 1003 | 9002 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
| 8 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
| 9 | 1004 | 9003 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
| 2 | 9002 | SQL | easy | 60 | 2020-02-01 10:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
1 | select |
19.题目:
用户在牛客试卷作答区作答记录存储在表exam_record中,内容如下:
exam_record表(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分)
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-07-02 09:21:01 | 80 |
| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 5 | 1002 | 9001 | 2021-07-02 19:01:01 | 2021-07-02 19:30:01 | 82 |
| 6 | 1002 | 9002 | 2021-07-05 18:01:01 | 2021-07-05 18:59:02 | 90 |
请计算2021年每个月里试卷作答区用户平均月活跃天数avg_active_days和月度活跃人数mau,上面数据的示例输出如下:
| month | avg_active_days | mau |
|---|---|---|
| 202107 | 1.50 | 2 |
| 202109 | 1.25 | 4 |
解释:2021年7月有2人活跃,共活跃了3天(1001活跃1天,1002活跃2天),平均活跃天数1.5;2021年9月有4人活跃,共活跃了5天,平均活跃天数1.25,结果保留2位小数。
注:此处活跃指有交卷行为。
分析:
2021年每个月
用户平均月活跃天数—round((count(distinct uid, date_format(submit_time, ‘%y%m%d’))) / count(distinct uid),2)
思路:
用户平均月活跃天数 = 该月活跃总天数 / 月度活跃总人数
该月活跃总天数统计时,不能统计一天内有重复的uid(用户)且要求submit_time不能为null
因此要distinct去重
月度活跃人数—count(distinct er.uid)
1 | select |
注意:
round()函数的使用
date_format函数的使用
count函数的使用
- count(distinct col) 计算该列除 NULL 之外的不重复行数,注意 count(distinct col1, col2) 如果其中一列全为 NULL,那么即使另一列有不同的值,也返回为 0
20.题目:
现有一张题目练习记录表practice_record,示例内容如下:
| id | uid | question_id | submit_time | score |
|---|---|---|---|---|
| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
| 5 | 1003 | 8002 | 2021-08-01 19:38:01 | 80 |
请从中统计出2021年每个月里用户的月总刷题数month_q_cnt 和日均刷题数avg_day_q_cnt(按月份升序排序)以及该年的总体情况,示例数据输出如下:
| submit_month | month_q_cnt | avg_day_q_cnt |
|---|---|---|
| 202108 | 2 | 0.065 |
| 202109 | 3 | 0.100 |
| 2021汇总 | 5 | 0.161 |
解释:2021年8月共有2次刷题记录,日均刷题数为2/31=0.065(保留3位小数);2021年9月共有3次刷题记录,日均刷题数为3/30=0.100;2021年共有5次刷题记录(年度汇总平均无实际意义,这里我们按照31天来算5/31=0.161)
参考答案
1 | select |
dayofmonth函数的使用
21. 题目:
现有试卷作答记录表exam_record(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分),示例数据如下:
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-07-02 09:21:01 | 80 |
| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 5 | 1002 | 9001 | 2021-07-02 19:01:01 | 2021-07-02 19:30:01 | 82 |
| 6 | 1002 | 9002 | 2021-07-05 18:01:01 | 2021-07-05 18:59:02 | 90 |
| 7 | 1003 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
| 8 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
| 9 | 1004 | 9003 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
| 10 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
| 11 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
| 12 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
| 13 | 1006 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
还有一张试卷信息表examination_info(exam_id试卷ID, tag试卷类别, difficulty试卷难度, duration考试时长, release_time发布时间),示例数据如下:
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
| 2 | 9002 | SQL | easy | 60 | 2020-02-01 10:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
请统计2021年每个未完成试卷作答数大于1的有效用户的数据(有效用户指完成试卷作答数至少为1且未完成数小于5),输出用户ID、未完成试卷作答数、完成试卷作答数、作答过的试卷tag集合,按未完成试卷数量由多到少排序。示例数据的输出结果如下:
| uid | incomplete_cnt | complete_cnt | detail |
|---|---|---|---|
| 1002 | 2 | 4 | 2021-09-01:算法;2021-07-02:SQL;2021-09-02:SQL;2021-09-05:SQL;2021-07-05:SQL |
解释:2021年的作答记录中,除了1004,其他用户均满足有效用户定义,但只有1002未完成试卷数大于1,因此只输出1002,detail中是1002作答过的试卷{日期:tag}集合,日期和tag间用:连接,多元素间用;连接。
分析:
- 未完成试卷作答数大于1—incomplete_cnt > 1
- 有效用户指完成试卷作答数至少为1且未完成数小于5—complete_cnt >= 1—incomplete_cnt < 5
- 作答过的试卷tag集合—group_concat(distinct concat_ws(‘:’, date(start_time), tag) SEPARATOR ‘;’)
- 按未完成试卷数量由多到少排序—order by incomplete_cnt DESC
1 | select |
注意:
group_concat(xxx)函数的使用
- 是将分组中括号里对应的字符串进行连接.如果分组中括号里的参数xxx有多行,那么就会将这多行的字符串连接,每个字符串之间会有特定的符号进行分隔。
22.题目:
现有试卷作答记录表exam_record(uid:用户ID, exam_id:试卷ID, start_time:开始作答时间, submit_time:交卷时间,没提交的话为NULL, score:得分),示例数据如下:
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | (NULL) | (NULL) |
| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | 2021-09-02 12:31:01 | 70 |
| 4 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
| 5 | 1002 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
| 6 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
| 7 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
| 8 | 1003 | 9001 | 2021-09-08 13:01:01 | (NULL) | (NULL) |
| 9 | 1003 | 9002 | 2021-09-08 14:01:01 | (NULL) | (NULL) |
| 10 | 1003 | 9003 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
| 11 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
| 12 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
| 13 | 1005 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
试卷信息表examination_info(exam_id:试卷ID, tag:试卷类别, difficulty:试卷难度, duration:考试时长, release_time:发布时间),示例数据如下:
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
| 2 | 9002 | C++ | easy | 60 | 2020-02-01 10:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
请从表中统计出 “当月均完成试卷数”不小于3的用户们爱作答的类别及作答次数,按次数降序输出,示例输出如下:
| tag | tag_cnt |
|---|---|
| C++ | 4 |
| SQL | 2 |
| 算法 | 1 |
解释:用户1002和1005在2021年09月的完成试卷数目均为3,其他用户均小于3;然后用户1002和1005作答过的试卷tag分布结果按作答次数降序排序依次为C++、SQL、算法。
分析:
- “当月均完成试卷数”不小于3—count(exam_id) / count(distinct DATE_FORMAT(submit_time, “%Y%m”)) >= 3
1 | select |
23.题目:
现有用户信息表user_info(uid用户ID,nick_name昵称, achievement成就值, level等级, job职业方向, register_time注册时间),示例数据如下:
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客1号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客2号 | 2100 | 6 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客3号 | 1500 | 5 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客4号 | 1100 | 4 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客5号 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
| 6 | 1006 | 牛客6号 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
释义:用户1001昵称为牛客1号,成就值为3100,用户等级是7级,职业方向为算法,注册时间2020-01-01 10:00:00
试卷信息表examination_info(exam_id试卷ID, tag试卷类别, difficulty试卷难度, duration考试时长, release_time发布时间) 示例数据如下:
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
| 2 | 9002 | C++ | easy | 60 | 2020-02-01 10:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
试卷作答记录表exam_record(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分) 示例数据如下:
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:41:01 | 70 |
| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | 2021-09-02 12:31:01 | 70 |
| 4 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 80 |
| 5 | 1002 | 9003 | 2021-08-01 12:01:01 | 2021-08-01 12:21:01 | 60 |
| 6 | 1002 | 9002 | 2021-08-02 12:01:01 | 2021-08-02 12:31:01 | 70 |
| 7 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 85 |
| 8 | 1002 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
| 9 | 1003 | 9002 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
| 10 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
| 11 | 1003 | 9003 | 2021-09-01 13:01:01 | 2021-09-01 13:41:01 | 70 |
| 12 | 1003 | 9001 | 2021-09-08 14:01:01 | (NULL) | (NULL) |
| 13 | 1003 | 9002 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
| 14 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 90 |
| 15 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
| 16 | 1005 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
请计算每张类别试卷发布后,当天5级以上的用户作答的人数uv和平均分avg_score,按人数降序,相同人数的按平均分升序,示例数据结果输出如下:
| exam_id | uv | avg_score |
|---|---|---|
| 9001 | 3 | 81.3 |
解释:只有一张SQL类别的试卷,试卷ID为9001,发布当天(2021-09-01)有1001、1002、1003、1005作答过,但是1003是5级用户,其他3位为5级以上,他们三的得分有[70,80,85,90],平均分为81.3(保留1位小数)。
分析:
- 当天5级以上的用户作答的人数
- 平均分avg_score—round(avg(temp_table.score), 1) as avg_score
- 按人数降序,按平均分升序—order by uv desc, avg_score asc
1 | select |
思考一下:
- 确定主表(数据的主要获取源
- 确定辅助表(可能用于子查询
- 描述中出现“每”,带有each意味的词,一般要使用group by
新 SQL 题(2024年)
SQL212
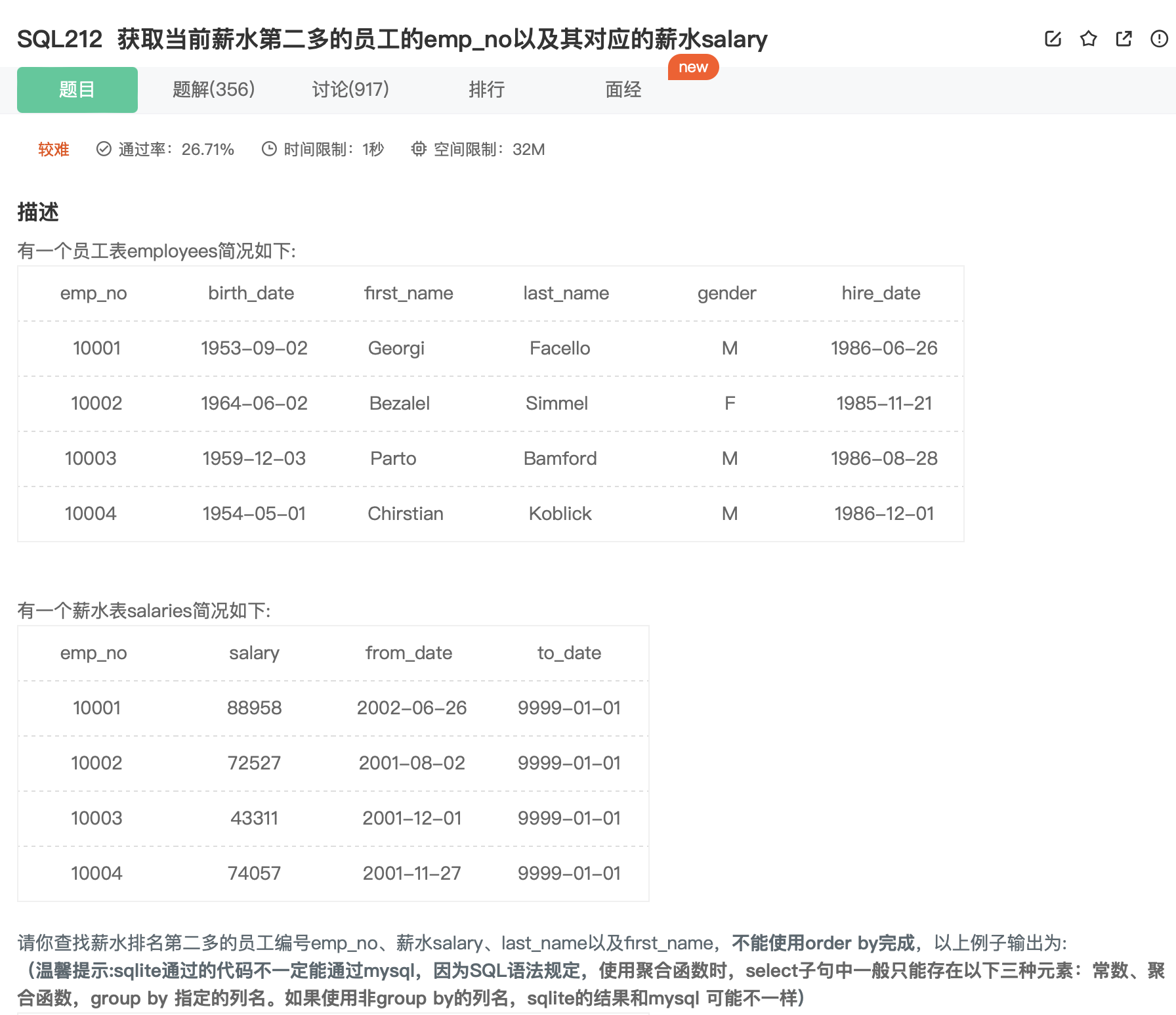
不是,哥们🦐,怎么不给用 order by啊…
思考:
- 将salaries 表自连接,不等式 salaries s1 join salaries s2 on s1.salary < s2.salary。每一行数据表示s1 表中的员工的工资低于 s2 表中的员工的。
- 要求薪水排名第二的员工,这意味着在前面只有一个员工的薪水高于要他,也就是说只要统计自连接表的行数即可(count(*) < 2)。
- 拿着第 2 步求的emp_no,作为筛查 salaries 和 employees 的条件即可求出。
上代码:
1 | select |
SQL215
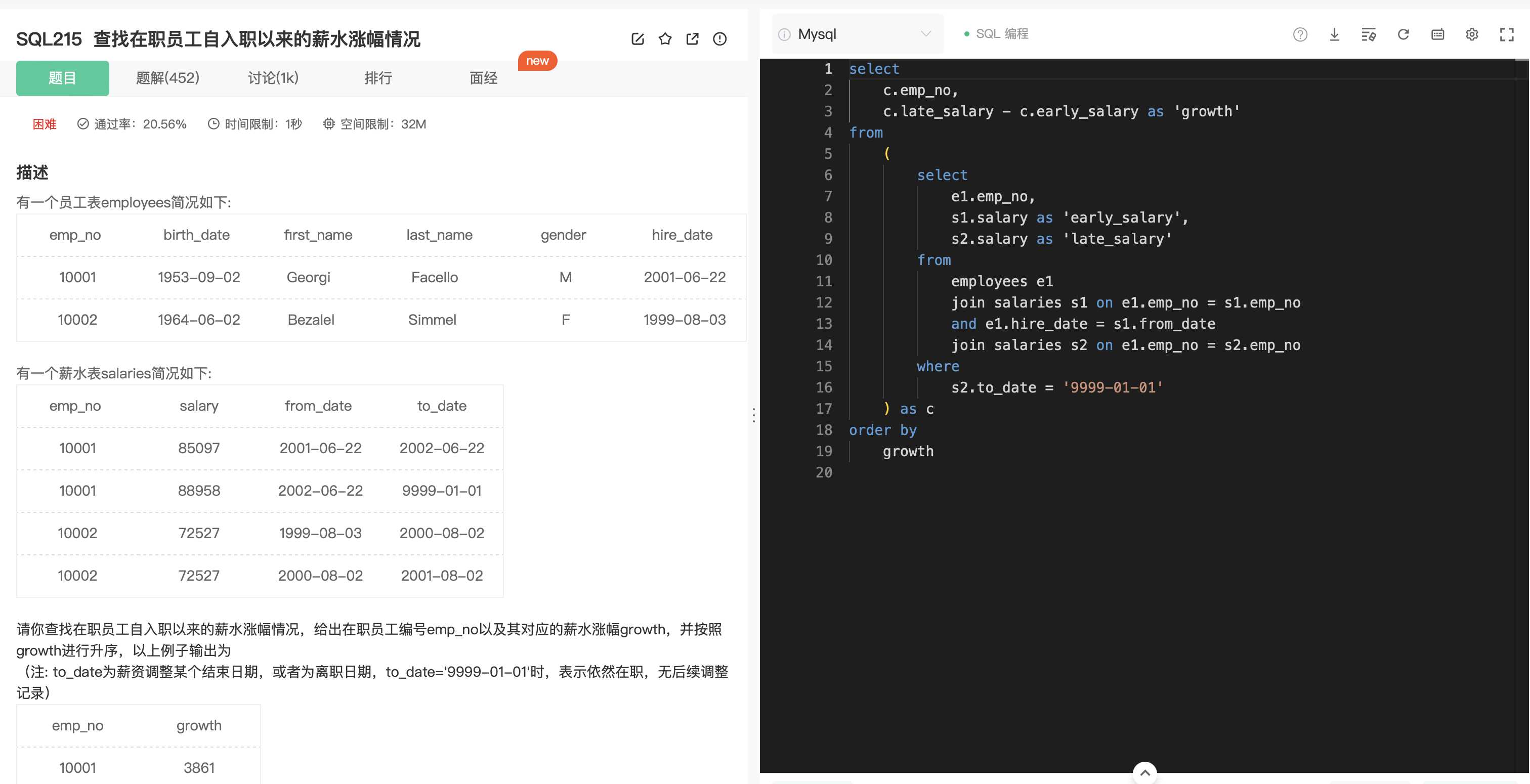
分析:
- 首先需要知道员工的初始工资 early_salary,内连接员工表和薪水表即可,连接条件为 hire_date = from_date。
- 求出最新工资,也就是需要薪水表的中 to_date为‘9999-01-01’的行。
- 将 1.中得到的表再与薪水表自连接。
思考:
- 是否有其他方法?能否只用一张表就能得到结果?这似乎是可以的,只需要在先按照员工分组,找到最小 from_date 对应的 salary,再找到 to_date 为‘9999-01-01’对应的 salary,两者作差即可。
SQL262
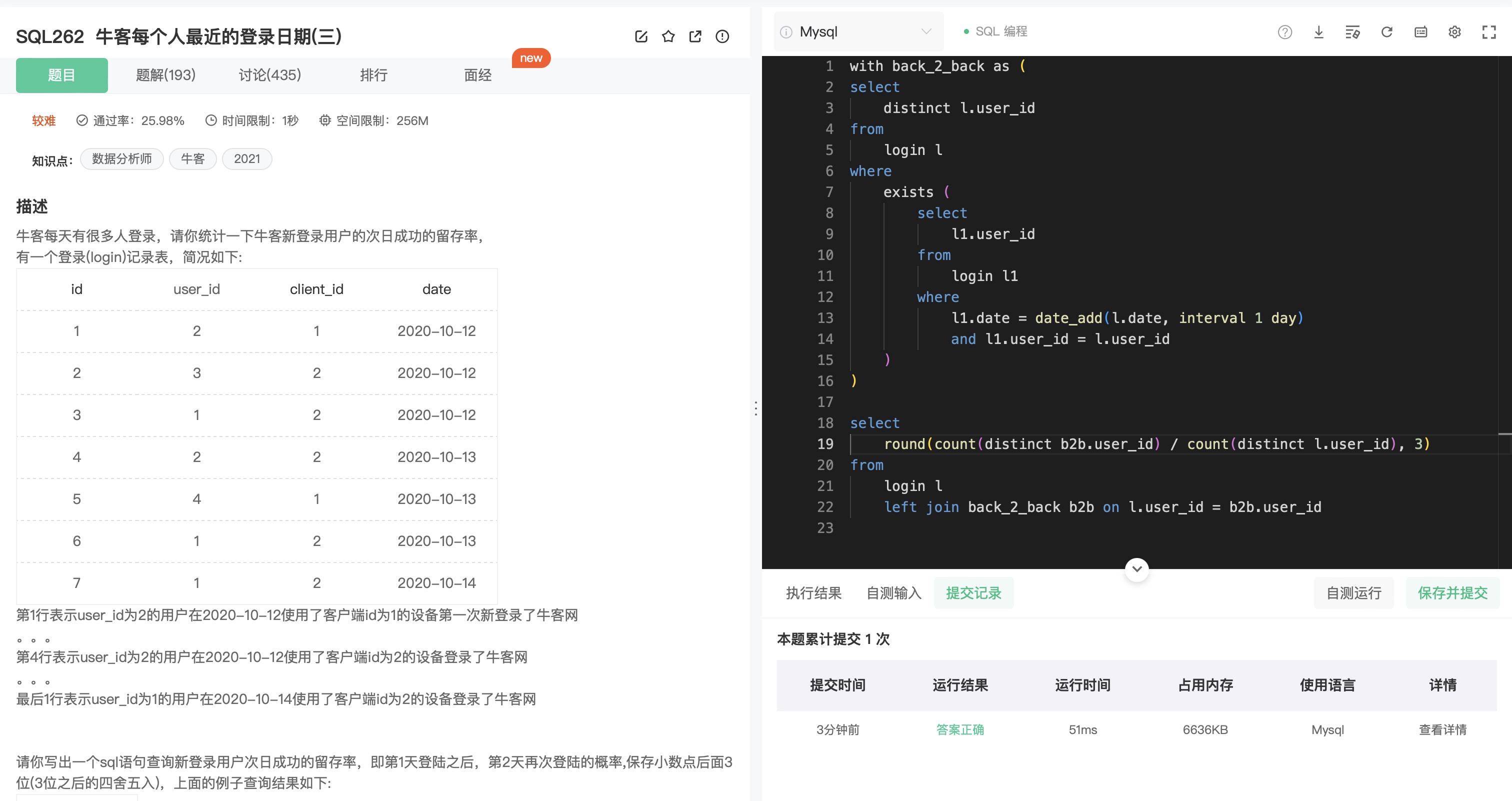
分析:
- 留存率 = count(distinct 连续登录两天的用户) / count(distinct 所有用户)。
- 创建临时表 back_2_back 找出连续登录两天的用户(重点)。
- 原表 left join 临时表,原表的 user_id 去重得到所有的用户,临时表的 user_id 去重得到目标用户。
思考:
- 第二步需要用到相关子查询,每读取一行,寻找该用户是否在当前日期的后一天有登录。
1 | with back_2_back as ( |
SQL263
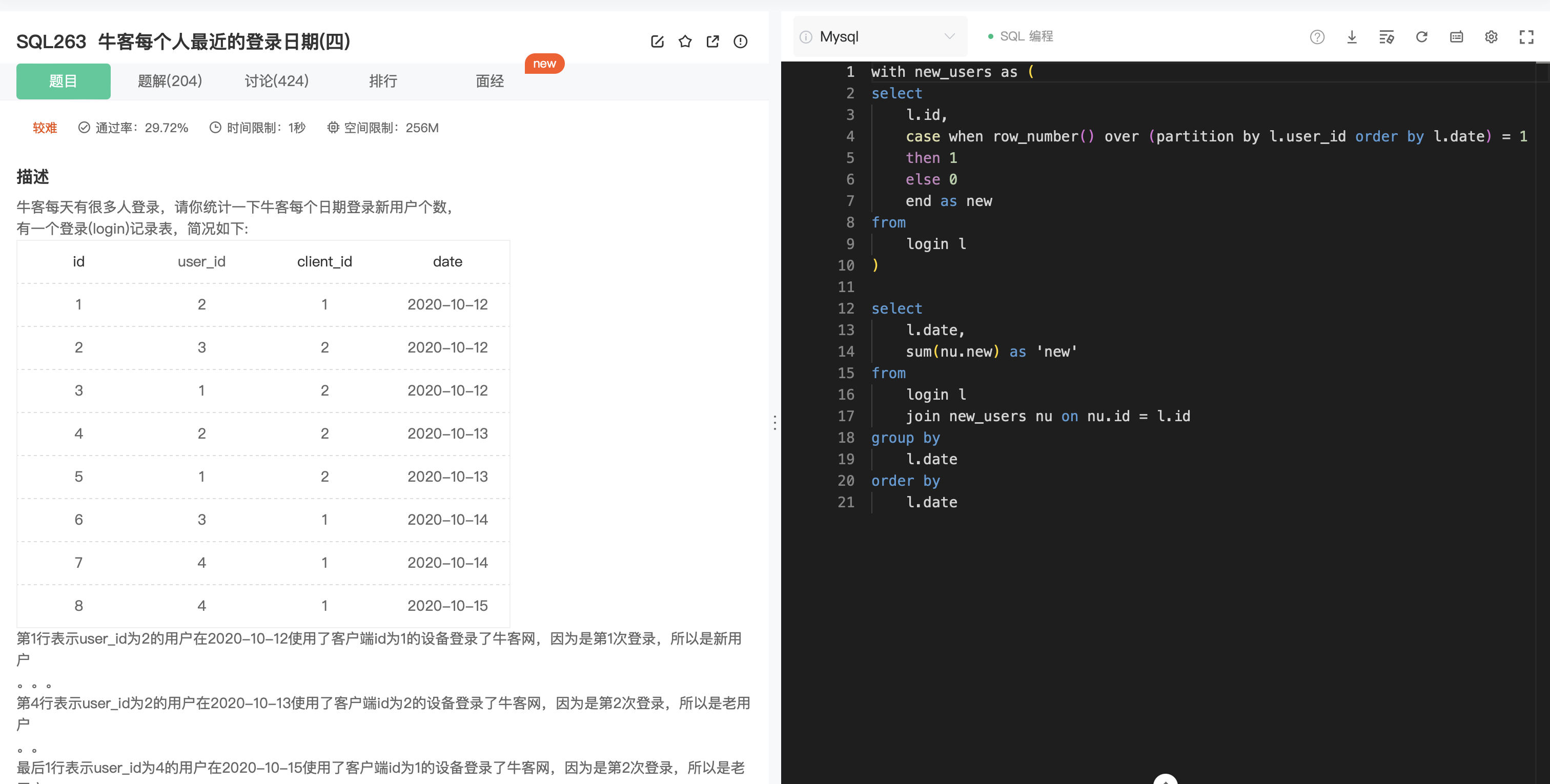
分析:
- 使用临时表找到最新的用户,什么是最新的用户。从时间上来看就是最先出现的用户。也就是说如果按照用户分组,然后每个组内再按照时间升序排列,排在第一的就是新用户。
- 将 1.中的表和原表通过 id 连接起来,接下来就是常规的 groupby 和 orderby。
思考:
- 第1步最重要,将用户分组,使用==窗口函数==。其次就是用==row_number== 函数给每1行排序好的数据1个行号,并使用 ==case when== 语句将行号为 1 的 user_id 标记为 1,新的列命名为 new。
SQL264
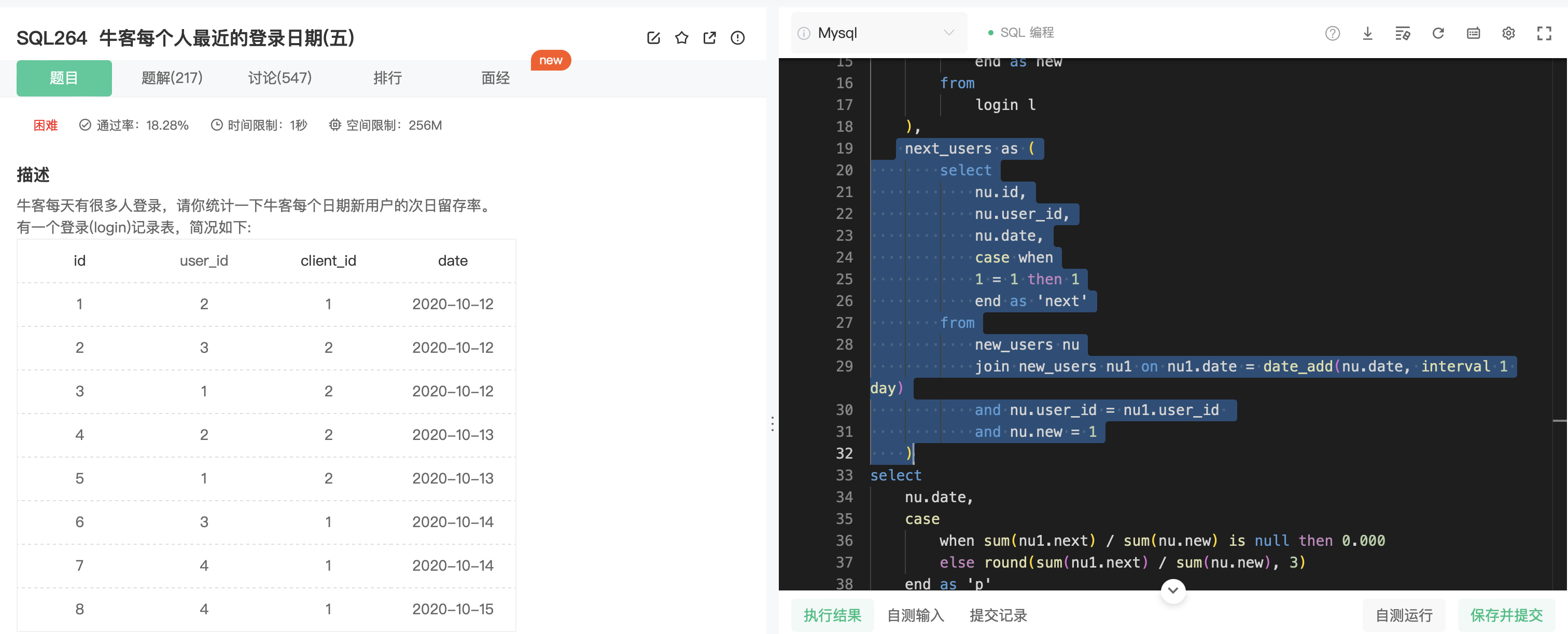
分析:
- 此题为上一题的强化版,多了一个“次日”的限制条件。重点就是如何筛选出符合“次日用户。
思考:
- 借助筛选出的新用户表 new_users,将其和原表连接得到 next_users,连接条件为相邻的日期(使用 data_add判别)且是同一个用户,且 new = 1。
- 然后给next_users添加新的列“next”,用来表示该用户在次日登录了。
- 最后将new_users和next_users通过唯一标识 id 连接,按日期分组,升序排列,分别计算 next 和 new 的个数即可。
SQL269
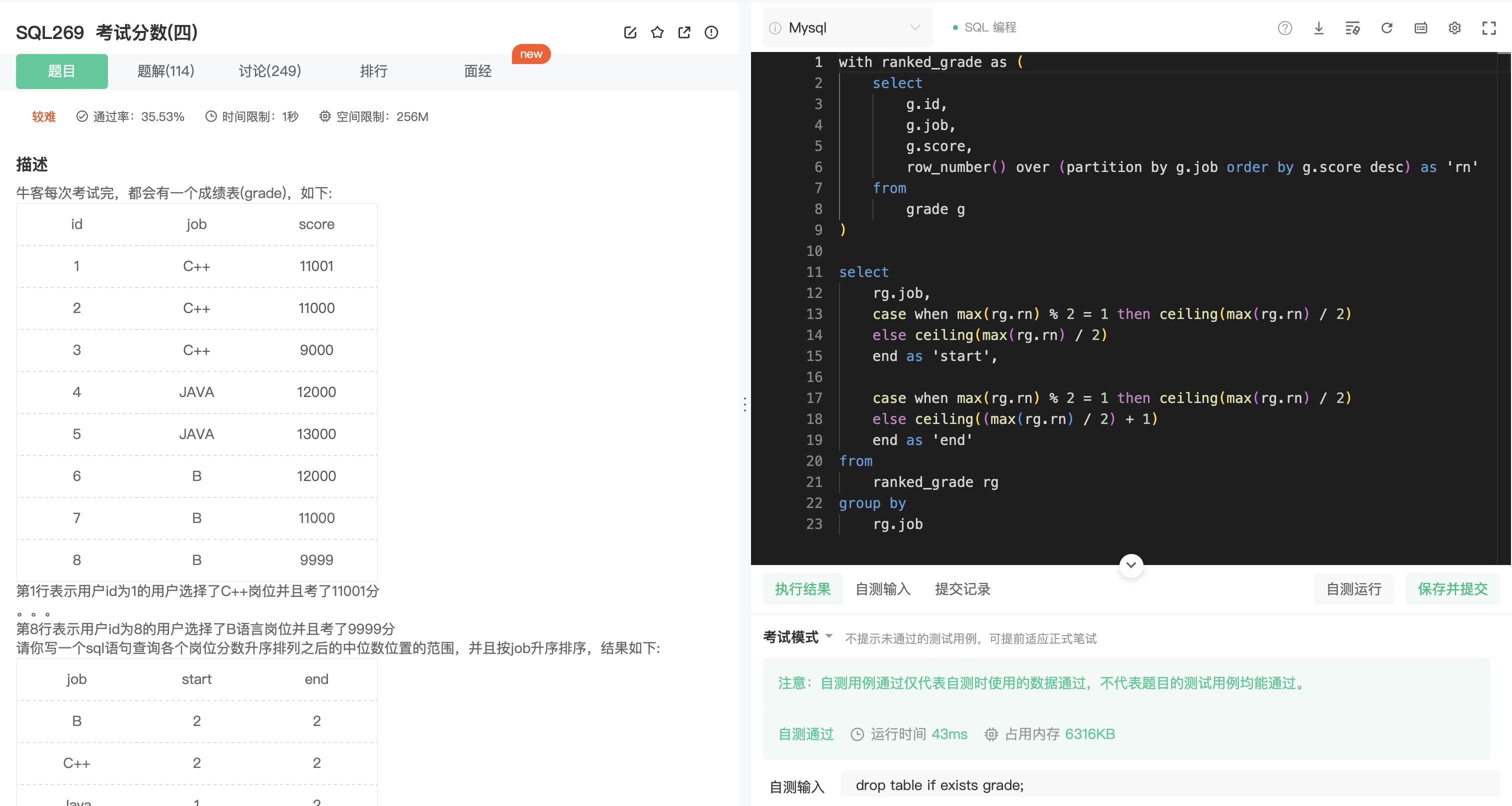
分析:
- 求解每个岗位的分数的中位数 median。
- 怎么表示中位数?
思考:
- 利用 row_number 窗口函数,按照 job 分组,score 升序(降序)排序,给每个 score 排名。
- 最大的序号为奇数时,最大序号除以 2 的结果使用 ceiling 函数得到中间的序号。
- 若最大的序号为偶数,最大序号除以 2 的结果 ceiling 一下得到较小的中位数位置 start,加 1 得到较大的中位数位置end。
SQL274
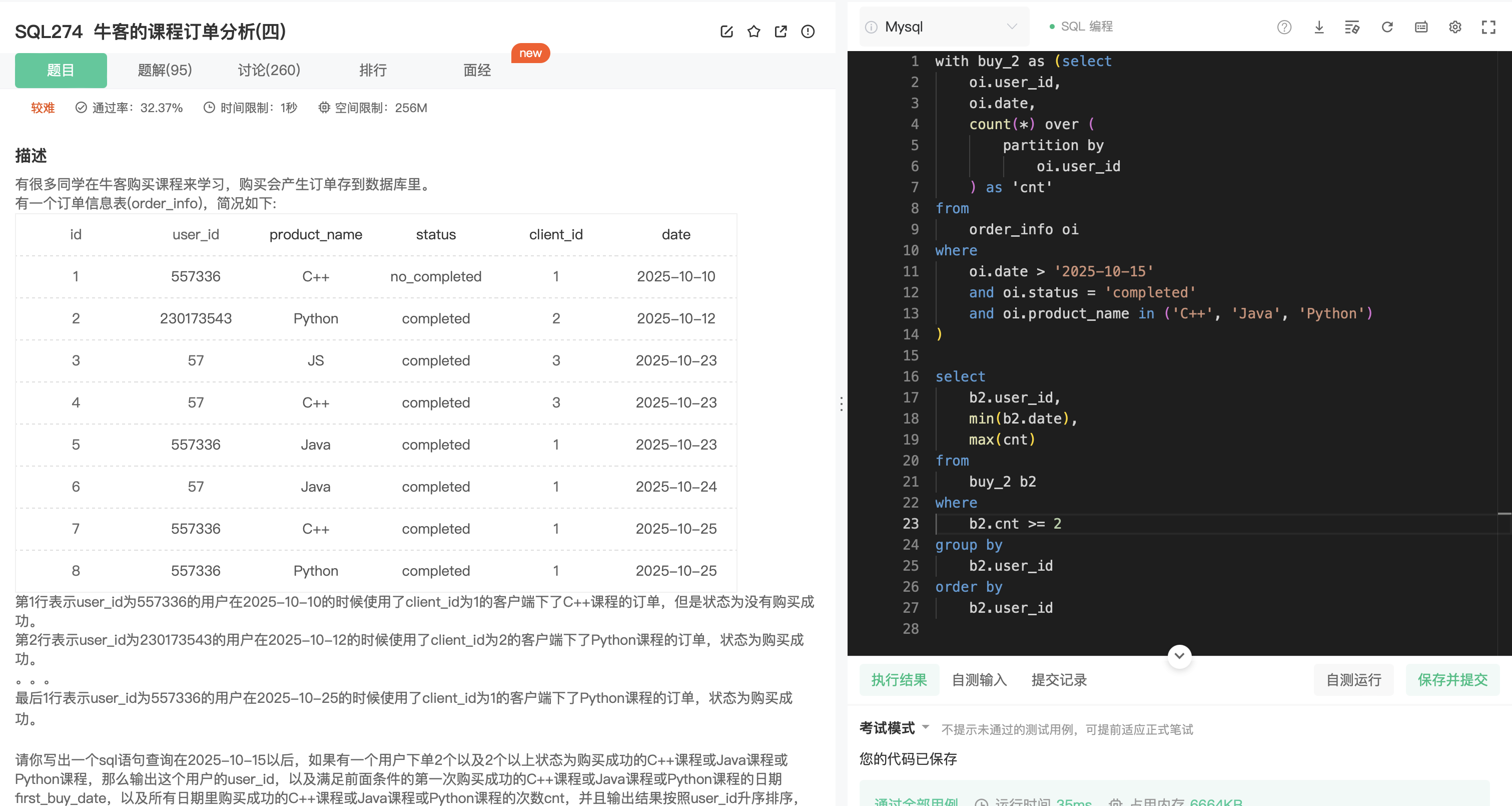
分析:
- 过滤“2025-10-15以后,如果有一个用户下单2个以及2个以上状态为购买成功的C++课程或Java课程或Python课程”。
- 统计每个用户一共买了几门课程(按user_id 分组)cnt。
思考:
- 通过以下条件创建派生表:
- 使用窗口函数统计每个用户买了几门课cnt。
- 用 where 过滤。
- 去除购买少于两门课程的 user,再按 user_id分组
- 第一次购买也就相当于购买日期最早,min(date)即可。
SQL275
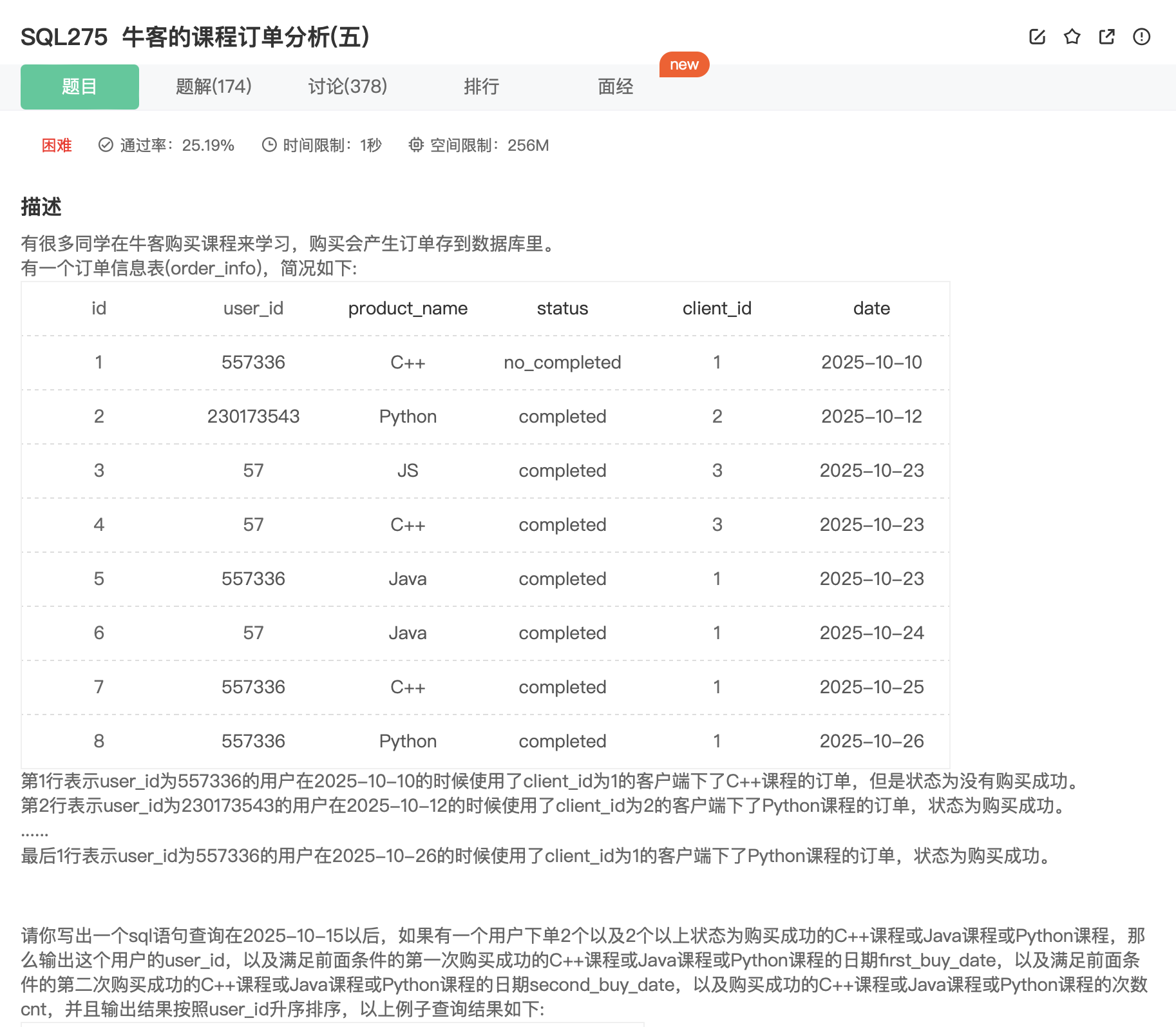
分析:
- 此题为上一题的强化版,难点在于如何找到第二次购买成功的日期。
思考:
- 可以利用窗口函数 row_number,先按 user_id 分区,在将按购买成功的日期升序排列,得到一列排序,其中序号 2 即为所求,再结合 case then,将其以原日期的形式标记出来,其余的为‘0000-00-00’标记。
- 接下来就是简单的 groupby 和 orderby。
SQL280
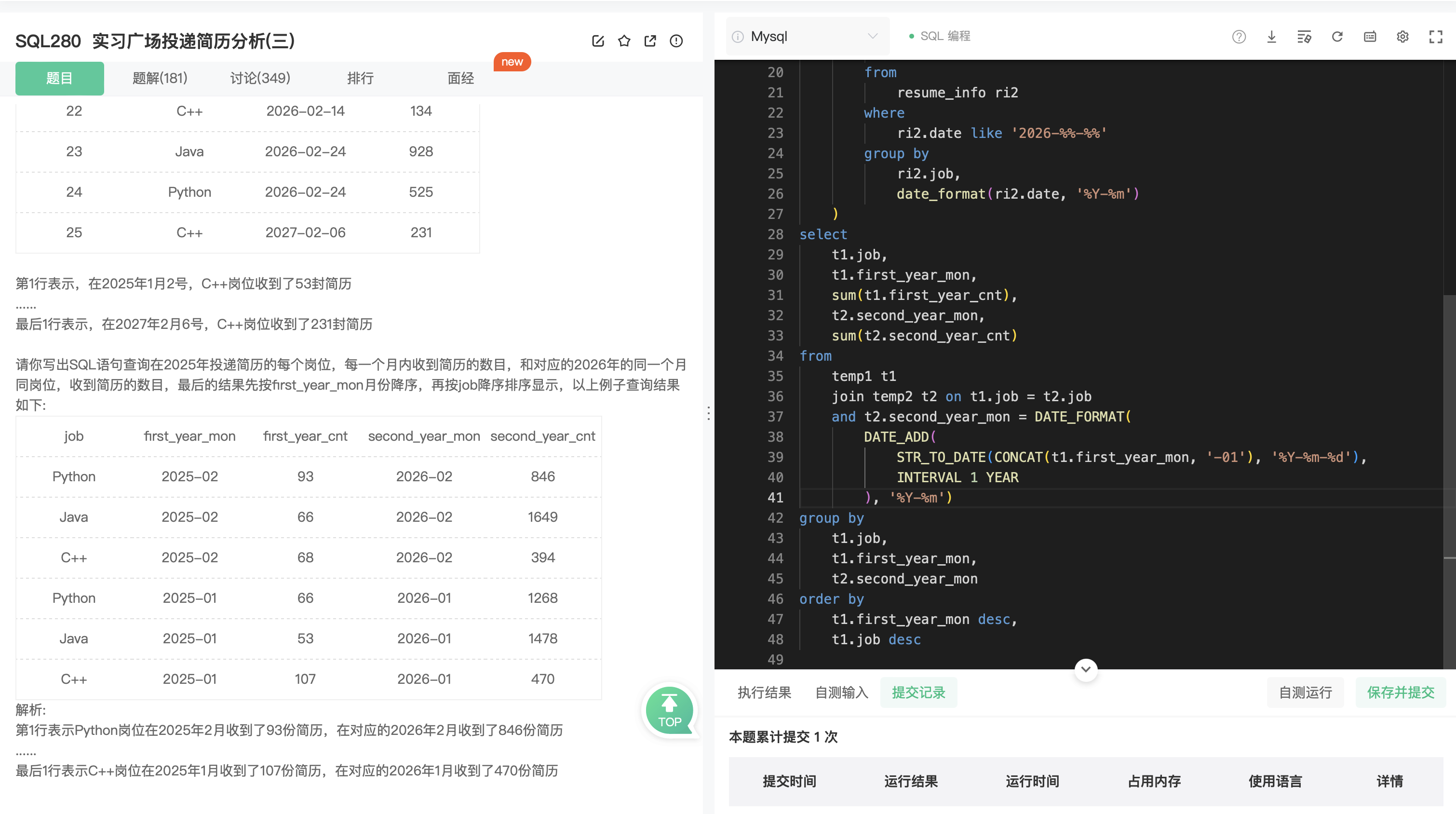
分析:
- 主要涉及到到日期的处理
- 同月份的后一年
思考:
- 用两张临时表,用 like 关键字过滤年份,一张表示 25 年每月数据,另外一张 为26 年。
- 两表连接,连接条件为:工作类型相同;temp1表年份加1等于temp2表的年份。先用 str_to_date将字符串转换为日期类型,再对其用 date_add做加法(1 年),最后使用 date_format 统一格式。
1 | with |
SQL281(有趣的规律)
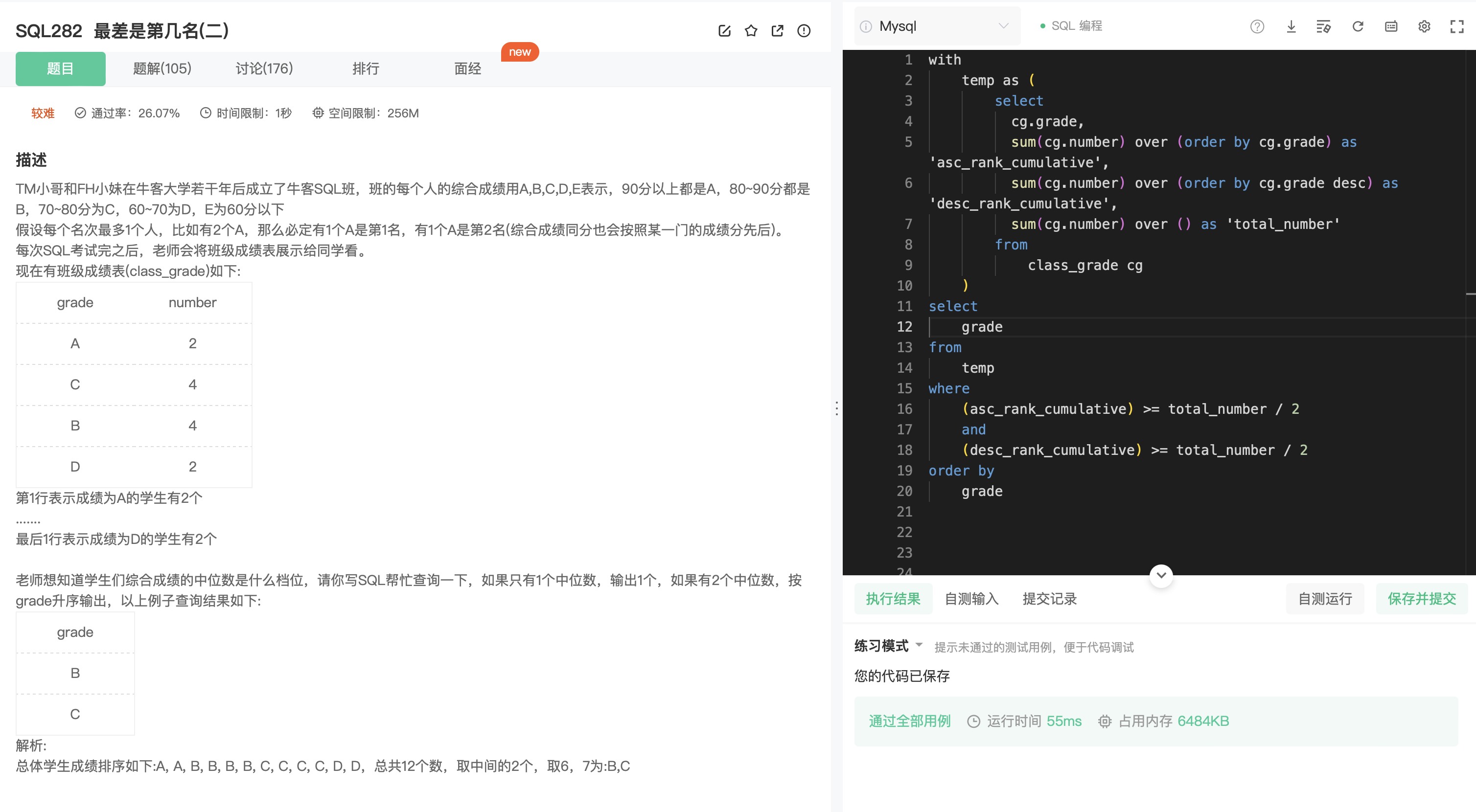
分析:
- 给出一组数和其对应的个数。
- 理论/关键点:当一个数的正序和倒序排列的对应的个数累计和均大于整个序列的数字个数的一半,那么这个数就是中位数。
扩展补充(另外一种情况):
- 若直接给出一组数A,要求这组数的中位数,只需将这组数的正序和倒序排列的序号分别相减得到另外一组数B。
- 若这组数A的个数为偶数个,则 数B中相减结果为 1 对应的数就是中位数。
- 若这组数A的个数为奇数个,则数B中相减结果为 0 对应的数就是中位数。
待证明…
SQL287
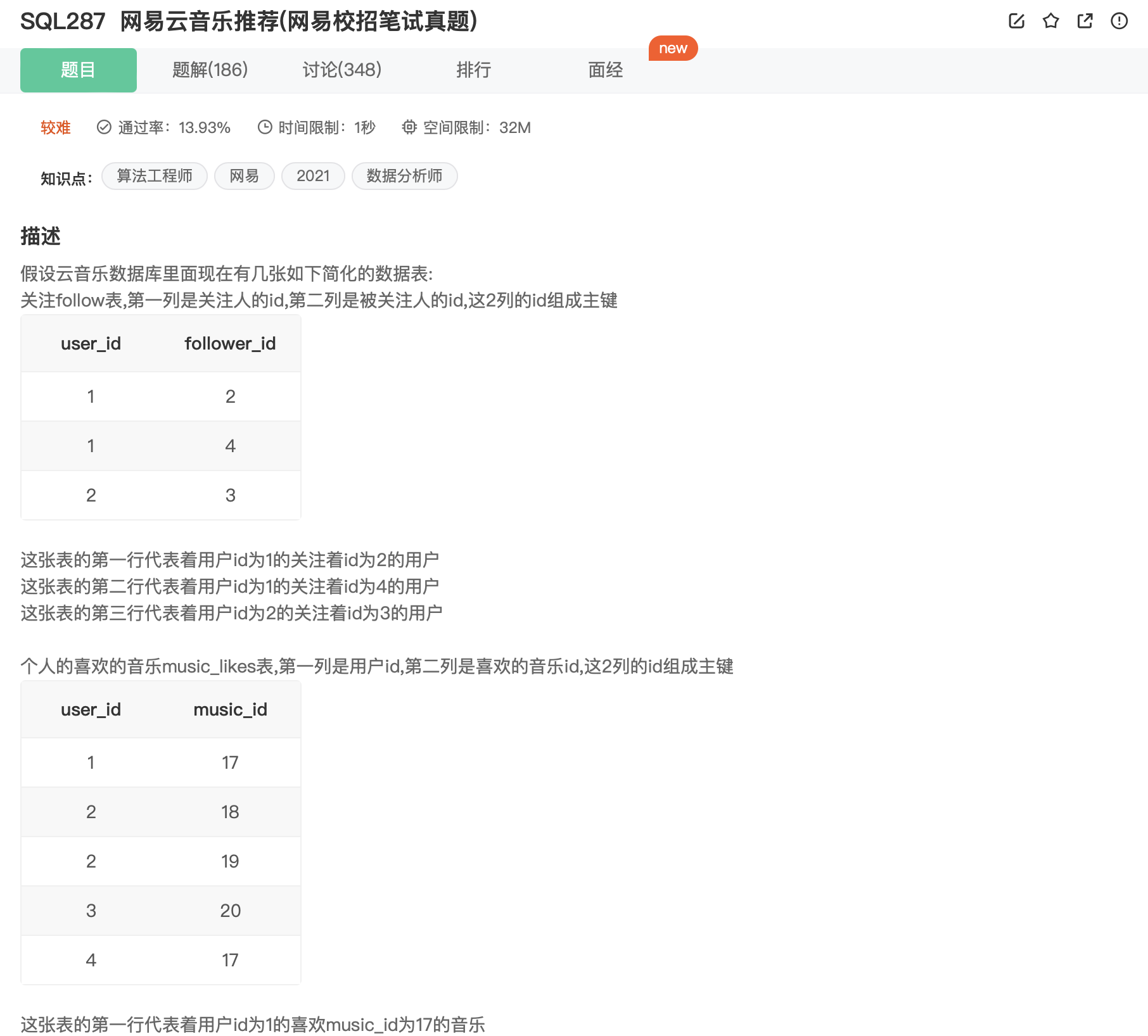

分析:
- 找到指定用户user_id = 1的喜欢的音乐music_id。
- 找到指定用户关注的用户的喜欢的音乐music_id。
- 将1.的 music_id右连接 2.的,得到的结果再和 music 连接。
思考: - 最关键的一步是去重,可以在 2.进行,也可以在 3.进行。
代码片段:
找到指定用户user_id = 1的喜欢的音乐music_id:
1 | with |
找到指定用户关注的用户的喜欢的音乐music_id(关键去重步骤):
1 | following_music as ( |
将1.的 music_id右连接 2.的,得到的结果再和 music 连接:
1 | result as ( |
完整代码:
1 | with |
新新SQL题(2025年)
最要命的一题
表:Employees
+—————-+———+
| Column Name | Type |
+—————-+———+
| employee_id | int |
| employee_name | varchar |
| manager_id | int |
| salary | int |
| department | varchar |
+—————-+———-+
employee_id 是这张表的唯一主键。
每一行包含关于一名员工的信息,包括他们的 ID,姓名,他们经理的 ID,薪水和部门。
顶级经理(CEO)的 manager_id 是空的。
编写一个解决方案来分析组织层级并回答下列问题:
- **层级:**对于每名员工,确定他们在组织中的层级(CEO 层级为
1,CEO 的直接下属员工层级为2,以此类推)。 - **团队大小:**对于每个是经理的员工,计算他们手下的(直接或间接下属)总员工数。
- **薪资预算:**对于每个经理,计算他们控制的总薪资预算(所有手下员工的工资总和,包括间接下属,加上自己的工资)。
返回结果表以 层级 升序 排序,然后以预算 降序 排序,最后以 employee_name 升序 排序。
结果格式如下所示。
示例:
输入:
Employees 表:
+————-+—————+————+——–+————-+
| employee_id | employee_name | manager_id | salary | department |
+————-+—————+————+——–+————-+
| 1 | Alice | null | 12000 | Executive |
| 2 | Bob | 1 | 10000 | Sales |
| 3 | Charlie | 1 | 10000 | Engineering |
| 4 | David | 2 | 7500 | Sales |
| 5 | Eva | 2 | 7500 | Sales |
| 6 | Frank | 3 | 9000 | Engineering |
| 7 | Grace | 3 | 8500 | Engineering |
| 8 | Hank | 4 | 6000 | Sales |
| 9 | Ivy | 6 | 7000 | Engineering |
| 10 | Judy | 6 | 7000 | Engineering |
+————-+—————+————+——–+————-+
输出:
+————-+—————+——-+———–+——–+
| employee_id | employee_name | level | team_size | budget |
+————-+—————+——-+———–+——–+
| 1 | Alice | 1 | 9 | 84500 |
| 3 | Charlie | 2 | 4 | 41500 |
| 2 | Bob | 2 | 3 | 31000 |
| 6 | Frank | 3 | 2 | 23000 |
| 4 | David | 3 | 1 | 13500 |
| 7 | Grace | 3 | 0 | 8500 |
| 5 | Eva | 3 | 0 | 7500 |
| 9 | Ivy | 4 | 0 | 7000 |
| 10 | Judy | 4 | 0 | 7000 |
| 8 | Hank | 4 | 0 | 6000 |
+————-+—————+——-+———–+——–+
解释:
- 组织结构:
- Alice(ID:1)是 CEO(层级 1)没有经理。
- Bob(ID:2)和 Charlie(ID:3)是 Alice 的直接下属(层级 2)
- David(ID:4),Eva(ID:5)从属于 Bob,而 Frank(ID:6)和 Grace(ID:7)从属于 Charlie(层级 3)
- Hank(ID:8)从属于 David,而 Ivy(ID:9)和 Judy(ID:10)从属于 Frank(层级 4)
- 层级计算:
- CEO(Alice)层级为 1
- 每个后续的管理层级都会使层级数加 1
- 团队大小计算:
- Alice 手下有 9 个员工(除她以外的整个公司)
- Bob 手下有 3 个员工(David,Eva 和 Hank)
- Charlie 手下有 4 个员工(Frank,Grace,Ivy 和 Judy)
- David 手下有 1 个员工(Hank)
- Frank 手下有 2 个员工(Ivy 和 Judy)
- Eva,Grace,Hank,Ivy 和 Judy 没有直接下属(team_size = 0)
- 预算计算:
- Alice 的预算:她的工资(12000)+ 所有员工的工资(72500)= 84500
- Charlie 的预算:他的工资(10000)+ Frank 的预算(23000)+ Grace 的工资(8500)= 41500
- Bob 的预算:他的工资 (10000) + David 的预算(13500)+ Eva 的工资(7500)= 31000
- Frank 的预算:他的工资 (9000) + Ivy 的工资(7000)+ Judy 的工资(7000)= 23000
- David 的预算:他的工资 (7500) + Hank 的工资(6000)= 13500
- 没有直接下属的员工的预算等于他们自己的工资。
1 | # 计算层级 |
第二高的薪水(ifnull方法的应用)
Employee 表:
+————-+——+
| Column Name | Type |
+————-+——+
| id | int |
| salary | int |
+————-+——+
id 是这个表的主键。
表的每一行包含员工的工资信息。
查询并返回 Employee 表中第二高的 不同 薪水 。如果不存在第二高的薪水,查询应该返回 null(Pandas 则返回 None) 。
查询结果如下例所示。
示例 1:
输入:
Employee 表:
+—-+——–+
| id | salary |
+—-+——–+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+—-+——–+
输出:
+———————+
| SecondHighestSalary |
+———————+
| 200 |
+———————+
示例 2:
输入:
Employee 表:
+—-+——–+
| id | salary |
+—-+——–+
| 1 | 100 |
+—-+——–+
输出:
+———————+
| SecondHighestSalary |
+———————+
| null |
+———————+
1 | select |
ifnull方法的应用:IFNULL() 函数用于判断第一个表达式是否为 NULL,如果为 NULL 则返回第二个参数的值,如果不为 NULL 则返回第一个参数的值。
题目描述的是,如果不存在第二高的薪水,则返回 null。
另有他法
1 | select |
连续出现的数字
表:Logs
+————-+———+
| Column Name | Type |
+————-+———+
| id | int |
| num | varchar |
+————-+———+
在 SQL 中,id 是该表的主键。
id 是一个自增列。
找出所有至少连续出现三次的数字。
返回的结果表中的数据可以按 任意顺序 排列。
结果格式如下面的例子所示:
示例 1:
输入:
Logs 表:
+—-+—–+
| id | num |
+—-+—–+
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 1 |
| 6 | 2 |
| 7 | 2 |
+—-+—–+
输出:
Result 表:
+—————–+
| ConsecutiveNums |
+—————–+
| 1 |
+—————–+
**解释:**1 是唯一连续出现至少三次的数字。
1 | select distinct num as ConsecutiveNums |
计算首次登录的第二天再次登录的玩家的 比率
Table: Activity
+————–+———+
| Column Name | Type |
+————–+———+
| player_id | int |
| device_id | int |
| event_date | date |
| games_played | int |
+————–+———+
(player_id,event_date)是此表的主键(具有唯一值的列的组合)。
这张表显示了某些游戏的玩家的活动情况。
每一行是一个玩家的记录,他在某一天使用某个设备注销之前登录并玩了很多游戏(可能是 0)。
编写解决方案,报告在首次登录的第二天再次登录的玩家的 比率,四舍五入到小数点后两位。换句话说,你需要计算从首次登录日期开始至少连续两天登录的玩家的数量,然后除以玩家总数。
结果格式如下所示:
示例 1:
输入:
Activity table:
+———–+———–+————+————–+
| player_id | device_id | event_date | games_played |
+———–+———–+————+————–+
| 1 | 2 | 2016-03-01 | 5 |
| 1 | 2 | 2016-03-02 | 6 |
| 2 | 3 | 2017-06-25 | 1 |
| 3 | 1 | 2016-03-02 | 0 |
| 3 | 4 | 2018-07-03 | 5 |
+———–+———–+————+————–+
输出:
+———–+
| fraction |
+———–+
| 0.33 |
+———–+
解释:
只有 ID 为 1 的玩家在第一天登录后才重新登录,所以答案是 1/3 = 0.33
1 | with first_logins as ( |
2016年的投资
Insurance 表:
+————-+——-+
| Column Name | Type |
+————-+——-+
| pid | int |
| tiv_2015 | float |
| tiv_2016 | float |
| lat | float |
| lon | float |
+————-+——-+
pid 是这张表的主键(具有唯一值的列)。
表中的每一行都包含一条保险信息,其中:
pid 是投保人的投保编号。
tiv_2015 是该投保人在 2015 年的总投保金额,tiv_2016 是该投保人在 2016 年的总投保金额。
lat 是投保人所在城市的纬度。题目数据确保 lat 不为空。
lon 是投保人所在城市的经度。题目数据确保 lon 不为空。
编写解决方案报告 2016 年 (tiv_2016) 所有满足下述条件的投保人的投保金额之和:
- 他在 2015 年的投保额 (
tiv_2015) 至少跟一个其他投保人在 2015 年的投保额相同。 - 他所在的城市必须与其他投保人都不同(也就是说 (
lat, lon) 不能跟其他任何一个投保人完全相同)。
tiv_2016 四舍五入的 两位小数 。
查询结果格式如下例所示。
示例 1:
输入:
Insurance 表:
+—–+———-+———-+—–+—–+
| pid | tiv_2015 | tiv_2016 | lat | lon |
+—–+———-+———-+—–+—–+
| 1 | 10 | 5 | 10 | 10 |
| 2 | 20 | 20 | 20 | 20 |
| 3 | 10 | 30 | 20 | 20 |
| 4 | 10 | 40 | 40 | 40 |
+—–+———-+———-+—–+—–+
输出:
+———-+
| tiv_2016 |
+———-+
| 45.00 |
+———-+
解释:
表中的第一条记录和最后一条记录都满足两个条件。
tiv_2015 值为 10 与第三条和第四条记录相同,且其位置是唯一的。
第二条记录不符合任何一个条件。其 tiv_2015 与其他投保人不同,并且位置与第三条记录相同,这也导致了第三条记录不符合题目要求。
因此,结果是第一条记录和最后一条记录的 tiv_2016 之和,即 45 。
方法一:使用 concat 和子查询exists
1 | # 显示使用 concat 拼接经纬度loc |
方法二:使用窗口函数
1 | with tt as( |
树节点
表:Tree
+————-+——+
| Column Name | Type |
+————-+——+
| id | int |
| p_id | int |
+————-+——+
id 是该表中具有唯一值的列。
该表的每行包含树中节点的 id 及其父节点的 id 信息。
给定的结构总是一个有效的树。
树中的每个节点可以是以下三种类型之一:
- “Leaf”:节点是叶子节点。
- “Root”:节点是树的根节点。
- “lnner”:节点既不是叶子节点也不是根节点。
编写一个解决方案来报告树中每个节点的类型。
以 任意顺序 返回结果表。
结果格式如下所示。
示例 1:
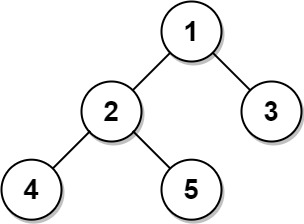
输入:
Tree table:
+—-+——+
| id | p_id |
+—-+——+
| 1 | null |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 2 |
+—-+——+
输出:
+—-+——-+
| id | type |
+—-+——-+
| 1 | Root |
| 2 | Inner |
| 3 | Leaf |
| 4 | Leaf |
| 5 | Leaf |
+—-+——-+
解释:
节点 1 是根节点,因为它的父节点为空,并且它有子节点 2 和 3。
节点 2 是一个内部节点,因为它有父节点 1 和子节点 4 和 5。
节点 3、4 和 5 是叶子节点,因为它们有父节点而没有子节点。
示例 2:

输入:
Tree table:
+—-+——+
| id | p_id |
+—-+——+
| 1 | null |
+—-+——+
输出:
+—-+——-+
| id | type |
+—-+——-+
| 1 | Root |
+—-+——-+
**解释:**如果树中只有一个节点,则只需要输出其根属性。
方法一:
1 | # 找到所有节点的子节点 |
方法二:
观察Tree table有以下三种情况:
在 p_id 一列中
- null:Root根
- id在p_id,Inner中间节点
- id不在p_id,Leaf叶子结点
1 | select id, |
换座位
表: Seat
+————-+———+
| Column Name | Type |
+————-+———+
| id | int |
| student | varchar |
+————-+———+id 是该表的主键(唯一值)列。
该表的每一行都表示学生的姓名和 ID。
ID 序列始终从 1 开始并连续增加。
编写解决方案来交换每两个连续的学生的座位号。如果学生的数量是奇数,则最后一个学生的id不交换。
按 id 升序 返回结果表。
查询结果格式如下所示。
示例 1:
输入:
Seat 表:
+—-+———+
| id | student |
+—-+———+
| 1 | Abbot |
| 2 | Doris |
| 3 | Emerson |
| 4 | Green |
| 5 | Jeames |
+—-+———+
输出:
+—-+———+
| id | student |
+—-+———+
| 1 | Doris |
| 2 | Abbot |
| 3 | Green |
| 4 | Emerson |
| 5 | Jeames |
+—-+———+
解释:
请注意,如果学生人数为奇数,则不需要更换最后一名学生的座位。
1 |
|
市场分析
表: Users
+—————-+———+
| Column Name | Type |
+—————-+———+
| user_id | int |
| join_date | date |
| favorite_brand | varchar |
+—————-+———+
user_id 是此表主键(具有唯一值的列)。
表中描述了购物网站的用户信息,用户可以在此网站上进行商品买卖。
表: Orders
+—————+———+
| Column Name | Type |
+—————+———+
| order_id | int |
| order_date | date |
| item_id | int |
| buyer_id | int |
| seller_id | int |
+—————+———+
order_id 是此表主键(具有唯一值的列)。
item_id 是 Items 表的外键(reference 列)。
(buyer_id,seller_id)是 User 表的外键。
表:Items
+—————+———+
| Column Name | Type |
+—————+———+
| item_id | int |
| item_brand | varchar |
+—————+———+
item_id 是此表的主键(具有唯一值的列)。
编写解决方案找出每个用户的注册日期和在 2019 年作为买家的订单总数。
以 任意顺序 返回结果表。
查询结果格式如下。
示例 1:
输入:
Users 表:
+———+————+—————-+
| user_id | join_date | favorite_brand |
+———+————+—————-+
| 1 | 2018-01-01 | Lenovo |
| 2 | 2018-02-09 | Samsung |
| 3 | 2018-01-19 | LG |
| 4 | 2018-05-21 | HP |
+———+————+—————-+
Orders 表:
+———-+————+———+———-+———–+
| order_id | order_date | item_id | buyer_id | seller_id |
+———-+————+———+———-+———–+
| 1 | 2019-08-01 | 4 | 1 | 2 |
| 2 | 2018-08-02 | 2 | 1 | 3 |
| 3 | 2019-08-03 | 3 | 2 | 3 |
| 4 | 2018-08-04 | 1 | 4 | 2 |
| 5 | 2018-08-04 | 1 | 3 | 4 |
| 6 | 2019-08-05 | 2 | 2 | 4 |
+———-+————+———+———-+———–+
Items 表:
+———+————+
| item_id | item_brand |
+———+————+
| 1 | Samsung |
| 2 | Lenovo |
| 3 | LG |
| 4 | HP |
+———+————+
输出:
+———–+————+—————-+
| buyer_id | join_date | orders_in_2019 |
+———–+————+—————-+
| 1 | 2018-01-01 | 1 |
| 2 | 2018-02-09 | 2 |
| 3 | 2018-01-19 | 0 |
| 4 | 2018-05-21 | 0 |
+———–+————+—————-+
错误例子
1 | select |
正确示范
1 | with register_date as ( |
正确示范得到的表如下所示:
| user_id | join_date | order_id | order_date | item_id | buyer_id | seller_id |
|---|---|---|---|---|---|---|
| 1 | 2018-01-01 | 1 | 2019-08-01 | 4 | 1 | 2 |
| 2 | 2018-02-09 | 6 | 2019-08-05 | 2 | 2 | 4 |
| 2 | 2018-02-09 | 3 | 2019-08-03 | 3 | 2 | 3 |
| 3 | 2018-01-19 | null | null | null | null | null |
| 4 | 2018-05-21 | null | null | null | null | null |
| 这样根据user_id分类,再count order_id 就可以得到结果。 |
学生们参加各科测试的次数
学生表: Students
+—————+———+
| Column Name | Type |
+—————+———+
| student_id | int |
| student_name | varchar |
+—————+———+
在 SQL 中,主键为 student_id(学生ID)。
该表内的每一行都记录有学校一名学生的信息。
科目表: Subjects
+————–+———+
| Column Name | Type |
+————–+———+
| subject_name | varchar |
+————–+———+
在 SQL 中,主键为 subject_name(科目名称)。
每一行记录学校的一门科目名称。
考试表: Examinations
+————–+———+
| Column Name | Type |
+————–+———+
| student_id | int |
| subject_name | varchar |
+————–+———+
这个表可能包含重复数据(换句话说,在 SQL 中,这个表没有主键)。
学生表里的一个学生修读科目表里的每一门科目。
这张考试表的每一行记录就表示学生表里的某个学生参加了一次科目表里某门科目的测试。
查询出每个学生参加每一门科目测试的次数,结果按 student_id 和 subject_name 排序。
查询结构格式如下所示。
示例 1:
输入:
Students table:
+————+————–+
| student_id | student_name |
+————+————–+
| 1 | Alice |
| 2 | Bob |
| 13 | John |
| 6 | Alex |
+————+————–+
Subjects table:
+————–+
| subject_name |
+————–+
| Math |
| Physics |
| Programming |
+————–+
Examinations table:
+————+————–+
| student_id | subject_name |
+————+————–+
| 1 | Math |
| 1 | Physics |
| 1 | Programming |
| 2 | Programming |
| 1 | Physics |
| 1 | Math |
| 13 | Math |
| 13 | Programming |
| 13 | Physics |
| 2 | Math |
| 1 | Math |
+————+————–+
输出:
+————+————–+————–+—————-+
| student_id | student_name | subject_name | attended_exams |
+————+————–+————–+—————-+
| 1 | Alice | Math | 3 |
| 1 | Alice | Physics | 2 |
| 1 | Alice | Programming | 1 |
| 2 | Bob | Math | 1 |
| 2 | Bob | Physics | 0 |
| 2 | Bob | Programming | 1 |
| 6 | Alex | Math | 0 |
| 6 | Alex | Physics | 0 |
| 6 | Alex | Programming | 0 |
| 13 | John | Math | 1 |
| 13 | John | Physics | 1 |
| 13 | John | Programming | 1 |
+————+————–+————–+—————-+
解释:
结果表需包含所有学生和所有科目(即便测试次数为0):
Alice 参加了 3 次数学测试, 2 次物理测试,以及 1 次编程测试;
Bob 参加了 1 次数学测试, 1 次编程测试,没有参加物理测试;
Alex 啥测试都没参加;
John 参加了数学、物理、编程测试各 1 次。
方法一:使用 union(比较耗时)
1 |
|
方法二:直接Students和Subjects笛卡尔积,再left join,然后直接groupby取数
1 | select |
计算以 7 天(某日期 + 该日期前的 6 天)为一个时间段的顾客消费平均值
表: Customer
+—————+———+
| Column Name | Type |
+—————+———+
| customer_id | int |
| name | varchar |
| visited_on | date |
| amount | int |
+—————+———+
在 SQL 中,(customer_id, visited_on) 是该表的主键。
该表包含一家餐馆的顾客交易数据。
visited_on 表示 (customer_id) 的顾客在 visited_on 那天访问了餐馆。
amount 是一个顾客某一天的消费总额。
你是餐馆的老板,现在你想分析一下可能的营业额变化增长(每天至少有一位顾客)。
计算以 7 天(某日期 + 该日期前的 6 天)为一个时间段的顾客消费平均值。average_amount 要 保留两位小数。
结果按 visited_on 升序排序。
返回结果格式的例子如下。
示例 1:
输入:
Customer 表:
+————-+————–+————–+————-+
| customer_id | name | visited_on | amount |
+————-+————–+————–+————-+
| 1 | Jhon | 2019-01-01 | 100 |
| 2 | Daniel | 2019-01-02 | 110 |
| 3 | Jade | 2019-01-03 | 120 |
| 4 | Khaled | 2019-01-04 | 130 |
| 5 | Winston | 2019-01-05 | 110 |
| 6 | Elvis | 2019-01-06 | 140 |
| 7 | Anna | 2019-01-07 | 150 |
| 8 | Maria | 2019-01-08 | 80 |
| 9 | Jaze | 2019-01-09 | 110 |
| 1 | Jhon | 2019-01-10 | 130 |
| 3 | Jade | 2019-01-10 | 150 |
+————-+————–+————–+————-+
输出:
+————–+————–+—————-+
| visited_on | amount | average_amount |
+————–+————–+—————-+
| 2019-01-07 | 860 | 122.86 |
| 2019-01-08 | 840 | 120 |
| 2019-01-09 | 840 | 120 |
| 2019-01-10 | 1000 | 142.86 |
+————–+————–+—————-+
解释:
第一个七天消费平均值从 2019-01-01 到 2019-01-07 是restaurant-growth/restaurant-growth/ (100 + 110 + 120 + 130 + 110 + 140 + 150)/7 = 122.86
第二个七天消费平均值从 2019-01-02 到 2019-01-08 是 (110 + 120 + 130 + 110 + 140 + 150 + 80)/7 = 120
第三个七天消费平均值从 2019-01-03 到 2019-01-09 是 (120 + 130 + 110 + 140 + 150 + 80 + 110)/7 = 120
第四个七天消费平均值从 2019-01-04 到 2019-01-10 是 (130 + 110 + 140 + 150 + 80 + 110 + 130 + 150)/7 = 142.86
1 | # 使用 groupby 先将每一天的营业额计算出来 |
查看推荐产品对
表:ProductPurchases
+————-+——+
| Column Name | Type |
+————-+——+
| user_id | int |
| product_id | int |
| quantity | int |
+————-+——+
(user_id, product_id) 是这张表的唯一主键。
每一行代表用户以特定数量购买的产品。
表:ProductInfo
+————-+———+
| Column Name | Type |
+————-+———+
| product_id | int |
| category | varchar |
| price | decimal |
+————-+———+
product_id 是这张表的唯一主键。
每一行表示一个产品的类别和价格。
亚马逊希望根据 共同购买模式 实现 “购买此商品的用户还购买了…” 功能。编写一个解决方案以实现:
- 识别 被同一客户一起频繁购买的 不同 产品对(其中
product1_id<product2_id) - 对于 每个产品对,确定有多少客户购买了这两种产品
如果 至少有 3 位不同的 客户同时购买了这两种产品,则认为该 产品对 适合推荐。
返回结果表以 customer_count 降序 排序,并且为了避免排序持平,以 product1_id 升序 排序,并以 product2_id 升序 排序。
结果格式如下所示。
示例:
输入:
ProductPurchases 表:
+———+————+———-+
| user_id | product_id | quantity |
+———+————+———-+
| 1 | 101 | 2 |
| 1 | 102 | 1 |
| 1 | 103 | 3 |
| 2 | 101 | 1 |
| 2 | 102 | 5 |
| 2 | 104 | 1 |
| 3 | 101 | 2 |
| 3 | 103 | 1 |
| 3 | 105 | 4 |
| 4 | 101 | 1 |
| 4 | 102 | 1 |
| 4 | 103 | 2 |
| 4 | 104 | 3 |
| 5 | 102 | 2 |
| 5 | 104 | 1 |
+———+————+———-+
ProductInfo 表:
+————+————-+——-+
| product_id | category | price |
+————+————-+——-+
| 101 | Electronics | 100 |
| 102 | Books | 20 |
| 103 | Clothing | 35 |
| 104 | Kitchen | 50 |
| 105 | Sports | 75 |
+————+————-+——-+
输出:
+————-+————-+——————-+——————-+—————-+
| product1_id | product2_id | product1_category | product2_category | customer_count |
+————-+————-+——————-+——————-+—————-+
| 101 | 102 | Electronics | Books | 3 |
| 101 | 103 | Electronics | Clothing | 3 |
| 102 | 104 | Books | Kitchen | 3 |
+————-+————-+——————-+——————-+—————-+
解释:
- 产品对 (101, 102):
- 被用户 1,2 和 4 购买(3 个消费者)
- 产品 101 属于电子商品类别
- 产品 102 属于图书类别
- 产品对 (101, 103):
- 被用户 1,3 和 4 购买(3 个消费者)
- 产品 101 属于电子商品类别
- 产品 103 属于服装类别
- 产品对 (102, 104):
- 被用户 2,4 和 5 购买(3 个消费者)
- 产品 102 属于图书类别
- 产品 104 属于厨房用品类别
结果以 customer_count 降序排序。对于有相同 customer_count 的产品对,将它们以 product1_id 升序排序,然后以 product2_id 升序排序。
1 | # 每个用户购买产品的信息 |
寻找持续进步的员工
表:employees
+————-+———+
| Column Name | Type |
+————-+———+
| employee_id | int |
| name | varchar |
+————-+———+
employee_id 是这张表的唯一主键。
每一行包含一名员工的信息。
表:performance_reviews
+————-+——+
| Column Name | Type |
+————-+——+
| review_id | int |
| employee_id | int |
| review_date | date |
| rating | int |
+————-+——+
review_id 是这张表的唯一主键。
每一行表示一名员工的绩效评估。评分在 1-5 的范围内,5分代表优秀,1分代表较差。
编写一个解决方案,以找到在过去三次评估中持续提高绩效的员工。
- 员工 至少需要
3次评估 才能被考虑 - 员工过去的
3次评估,评分必须 严格递增(每次评价都比上一次好) - 根据
review_date为每位员工分析最近的3次评估 - 进步分数 为最后
3次评估中最后一次评分与最早一次评分之间的差值
返回结果表以 进步分数 降序 排序,然后以 名字 升序 排序。
结果格式如下所示。
示例:
输入:
employees 表:
+————-+—————-+
| employee_id | name |
+————-+—————-+
| 1 | Alice Johnson |
| 2 | Bob Smith |
| 3 | Carol Davis |
| 4 | David Wilson |
| 5 | Emma Brown |
+————-+—————-+
performance_reviews 表:
+———–+————-+————-+——–+
| review_id | employee_id | review_date | rating |
+———–+————-+————-+——–+
| 1 | 1 | 2023-01-15 | 2 |
| 2 | 1 | 2023-04-15 | 3 |
| 3 | 1 | 2023-07-15 | 4 |
| 4 | 1 | 2023-10-15 | 5 |
| 5 | 2 | 2023-02-01 | 3 |
| 6 | 2 | 2023-05-01 | 2 |
| 7 | 2 | 2023-08-01 | 4 |
| 8 | 2 | 2023-11-01 | 5 |
| 9 | 3 | 2023-03-10 | 1 |
| 10 | 3 | 2023-06-10 | 2 |
| 11 | 3 | 2023-09-10 | 3 |
| 12 | 3 | 2023-12-10 | 4 |
| 13 | 4 | 2023-01-20 | 4 |
| 14 | 4 | 2023-04-20 | 4 |
| 15 | 4 | 2023-07-20 | 4 |
| 16 | 5 | 2023-02-15 | 3 |
| 17 | 5 | 2023-05-15 | 2 |
+———–+————-+————-+——–+
输出:
+————-+—————-+——————-+
| employee_id | name | improvement_score |
+————-+—————-+——————-+
| 2 | Bob Smith | 3 |
| 1 | Alice Johnson | 2 |
| 3 | Carol Davis | 2 |
+————-+—————-+——————-+
解释:
- Alice Johnson (employee_id = 1):
- 有 4 次评估,分数:2, 3, 4, 5
- 最后 3 次评估(按日期):2023-04-15 (3), 2023-07-15 (4), 2023-10-15 (5)
- 评分严格递增:3 → 4 → 5
- 进步分数:5 - 3 = 2
- Carol Davis (employee_id = 3):
- 有 4 次评估,分数:1, 2, 3, 4
- 最后 3 次评估(按日期):2023-06-10 (2),2023-09-10 (3),2023-12-10 (4)
- 评分严格递增:2 → 3 → 4
- 进步分数:4 - 2 = 2
- Bob Smith (employee_id = 2):
- 有 4 次评估,分数:3,2,4,5
- 最后 3 次评估(按日期):2023-05-01 (2),2023-08-01 (4),2023-11-01 (5)
- 评分严格递增:2 → 4 → 5
- 进步分数:5 - 2 = 3
- 未包含的员工:
- David Wilson (employee_id = 4):之前 3 次评估都是 4 分(没有进步)
- Emma Brown (employee_id = 5):只有 2 次评估(需要至少 3 次)
输出表以 improvement_score 降序排序,然后以 name 升序排序。
1 | # 先选出至少评估三次的员工id |
- 修正示例
为避免重复列名错误,可以明确列出需要的列,并使用别名来避免列名冲突:
1 | SELECT de.dept_no, de.emp_no AS dept_emp_no, s.salary, s.emp_no AS salary_emp_no FROM dept_emp de JOIN salaries s ON de.emp_no = s.emp_no; |
在这个修正后的查询中:
de.emp_no被重命名为dept_emp_no。s.emp_no被重命名为salary_emp_no。
这样可以避免列名冲突,同时明确结果集中每列的来源。
总结
使用 SELECT * 时,尤其在连接操作中,可能会导致 “Duplicate column name” 错误。明确列出所需的列,并使用别名来处理重复的列名,是解决此问题的有效方法。此外,明确列出列名也有助于提高查询性能和结果的清晰度。
目标表和子查询表冲突
目标表和子查询表冲突
- 错误信息:
You can't specify target table 'table_name' for update in FROM clause - 原因: 你在
UPDATE操作中试图直接引用并更新同一个表,这种操作在 MySQL 中是不允许的,因为可能导致数据不一致或逻辑错误。 - 示例:
UPDATE table_name SET column = (SELECT column FROM table_name WHERE condition);
- 错误信息:
在
UPDATE中的JOIN引用错误- 错误信息:
You can't specify target table 'table_name' for update in JOIN clause - 原因: 与目标表进行连接操作时,如果直接在
JOIN子句中引用目标表,会出现类似的问题。 - 示例:
UPDATE table_name t1 JOIN table_name t2 ON t1.id = t2.id SET t1.column = t2.column WHERE t2.condition;
- 错误信息:
相关例题:
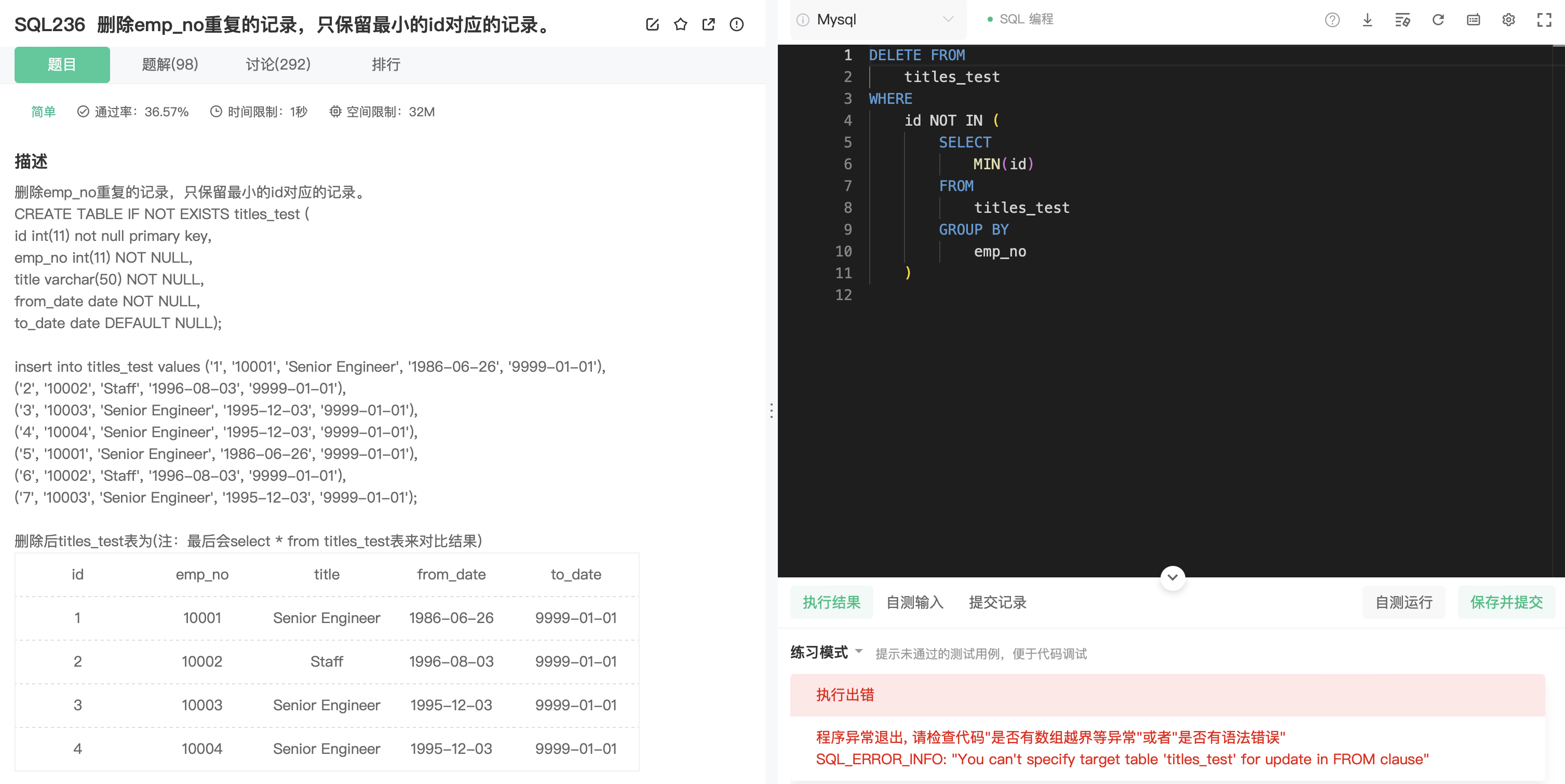
解决方案
使用临时表
步骤:
- 将子查询的结果存储到一个临时表中。
- 使用临时表的数据来更新目标表。
- 删除临时表。
使用派生表(Derived Table)
步骤:
- 使用
WITH子句(公用表表达式,CTE)创建一个临时结果集。 - 基于这个临时结果集执行更新操作。
- 使用
Tips:
选择使用临时表还是派生表取决于具体的需求。如果你需要在多个查询中复用数据或处理复杂的中间结果,临时表可能更合适。而如果你只是需要在单个查询中临时处理数据,派生表则可以简化查询逻辑。
SQL 窗口函数中,聚合函数结合 ORDER BY使用时,会受到 ORDER BY的影响
1. 累积计算(Running Total)
- 影响: 当聚合函数与
ORDER BY一起使用时,可以对窗口中的每一行计算一个累积的值。例如,SUM()在按某列排序后,计算当前行及之前所有行的累积和。 - 示例:
1 | SUM(salary) OVER (ORDER BY hire_date) AS running_total_salary |
- 结果: 该查询为每一行计算一个累积的工资总和,随着行号的增加,累积和会不断增加。
2. 滑动窗口计算(Sliding Window Calculation)
- 影响:
ORDER BY可以与ROWS BETWEEN或RANGE BETWEEN子句结合使用,以定义一个滑动窗口。这个窗口会在每一行上滑动,并在窗口范围内执行聚合计算。 - 示例:
1 | AVG(salary) OVER (ORDER BY hire_date ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS moving_avg_salary |
- 结果: 该查询计算的是包括当前行和前一行在内的滑动平均工资。随着每行的移动,计算的窗口也会移动。
3. 按顺序的聚合(Ordered Aggregate)
- 影响: 聚合函数结合
ORDER BY使用,可以在指定顺序内按行计算。例如,计算按某个顺序的最小值或最大值。 - 示例:
1 | MAX(salary) OVER (ORDER BY hire_date) AS max_salary_to_date |
- 结果: 该查询为每一行计算按雇佣日期排序的最大工资,即截止到当前行的最大工资。
4. 使用 ROWS 或 RANGE 子句控制窗口大小
- 影响:
ORDER BY决定了窗口内的行的顺序,而ROWS或RANGE子句可以进一步定义在这个顺序中窗口的大小,从而影响聚合函数的计算范围。 - 示例:
1 | SUM(salary) OVER (ORDER BY hire_date RANGE BETWEEN INTERVAL '1' MONTH PRECEDING AND CURRENT ROW) AS monthly_salary_sum |
- 结果: 该查询在每一行上计算当前行及之前1个月内所有行的工资总和。
5. 与 PARTITION BY 结合使用
- 影响: 当聚合函数与
PARTITION BY和ORDER BY结合使用时,PARTITION BY会先将数据划分成不同的分区,ORDER BY再对分区内的数据进行排序,最终影响聚合函数的计算顺序。 - 示例:
1 | SUM(salary) OVER (PARTITION BY department ORDER BY hire_date) AS department_running_total |
- 结果: 该查询为每个部门计算按雇佣日期排序的累积工资总和。
总结
- 累积计算: 通过
ORDER BY影响聚合函数的累积值,如累计和(Running Total)、累计平均等。 - 滑动窗口: 结合
ORDER BY和ROWS/RANGE子句定义滑动窗口,计算指定范围内的聚合值。 - 按顺序的聚合: 在指定顺序内,计算逐行的最小值、最大值、总和等。
- 分区与排序结合:
PARTITION BY分区后,ORDER BY对分区内数据排序,影响聚合函数的计算。
SQL_ERROR_INFO: “Expression #1 of ORDER BY clause is not in SELECT list, references column ‘m.id’ which is not in SELECT list; this is incompatible with DISTINCT”
SQL 标准要求,在使用 DISTINCT 和 ORDER BY 时,ORDER BY 子句中提到的所有列必须出现在 SELECT 列表中。如果它们不在列表中,SQL 将无法执行排序,因为排序列在结果集中是不可见的。
• 不使用 DISTINCT 时:ORDER BY 的列 不需要 出现在 SELECT 列表中。
• 使用 DISTINCT 时:ORDER BY 的列 通常需要 出现在 SELECT 列表中。




