
蛋疼のNode学习之路(持续更新...)

蛋疼のNode学习之路(持续更新...)
Kitholt Frank蛋疼のNode学习之路(持续更新…)
Day1
Previously on ‘Preface’,对于一个几乎零基础的我来说,搭建博客的过程是十分痛苦的,这现在只是一个简单的修改博客主题和编辑的过程啊(前端知识盲区o(╥﹏╥)o)。所以我决定花上一定时间来学习Node.js。希望学完之后我能更好的运维我的BLog(顺便复【yu】习一下Web相关知识,HTML5,CSS3,JavaScript什么的都快忘光光啦)话不多说,今天开始第一天的学习!
①那么,Node.js是乜嘢?(what?)
解释:
不是一门语言,不是库,不是框架。而是一个js的运行时 ,通俗地说就是能够一个能够运行js的平台环境。
可提供服务器级别的api(需要引入相关的模块,比如文件读写需要’fs’,也就是File-System):文件读写,网络服务构建,网络通信,http服务器(http模块)……//后面会讲模块系统
特性:
- 事件驱动
- 非阻塞IO模型(异步)————————————-啊啥是同步和异步?,又要去恶补了o((⊙﹏⊙))o
- 轻量和高效
与Node.js相关的东东
npm:全称是Node Package Manager。世界上最大的开源生态系统(大多数的js相关的包都在npm里)可在命令行通过下列语法获取相关包
1 | npm install [jquery] |
②Node.js能干啥哇?(do what?)
web服务器后台(能干类似活的有Java,,PHP,Python,balabala…….)
命令行工具
- npm
- git
- hexo (这个我熟哈哈)
③参考资源(resource)
- 《深入浅出Node.js》(偏理论)
- 《Node.js权威指南》
- JavaScript标准参考教程(alpha)作者:阮一峰(惊了,英文名也叫Frank)
- Node入门(fen)
- cNode社区
④安装Node(install)
会的都会,不会的戳一戳下面的教程:
参考教程:https://www.runoob.com/nodejs/nodejs-install-setup.html
⑤模块系统(Module system)
在Node中,每一个js文件都是一个模块,另外Node中也没有全局作用域的概念。
在Node中,只能通过require()方法加载js文件。
require()方法只加载其中的代码。既然没有全局作用域,那么各个js文件之间是模块作用域。
- 模块全封闭。
- 外部和内部之间是无法互相访问的。
其实每个模块中有都一个exports专属的对象,该对象中可以封装各自模块中的数据和方法,方便其他模块应用
举个例子
1
var demo =require('./a')//调用模板a,并且获得a的exports对象,并且用一个变量demo接收
——————-分割线,下面进入简单的实操环节——————–
- 启动一个简单服务器
1 | var http = require('http')//创建http对象 |
但是第一次运行的时候出现这种情况…….
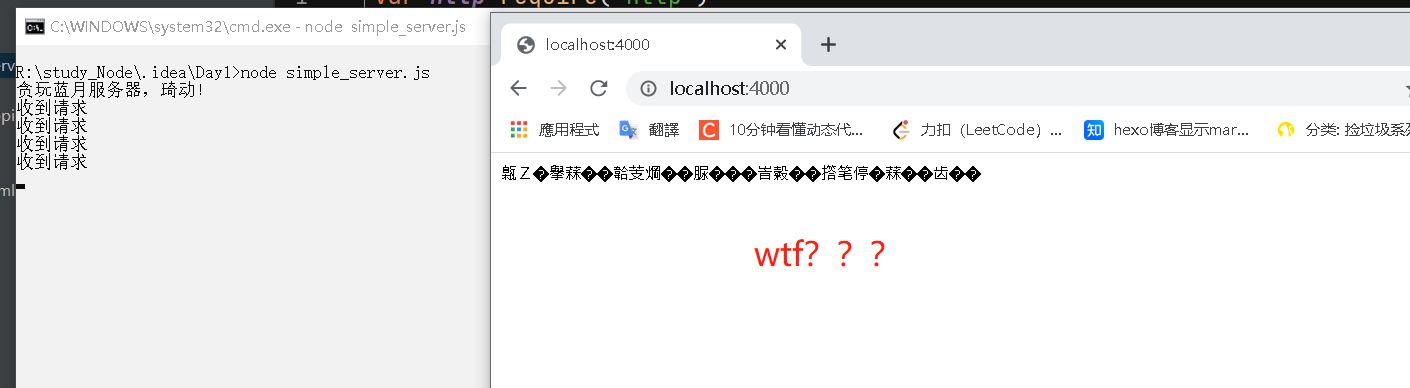
不用慌,在回调函数里的第一行加上
1 | response.writeHeader(200, {'Content-Type': 'text/html;charset=utf-8'}) |
运行后的截图
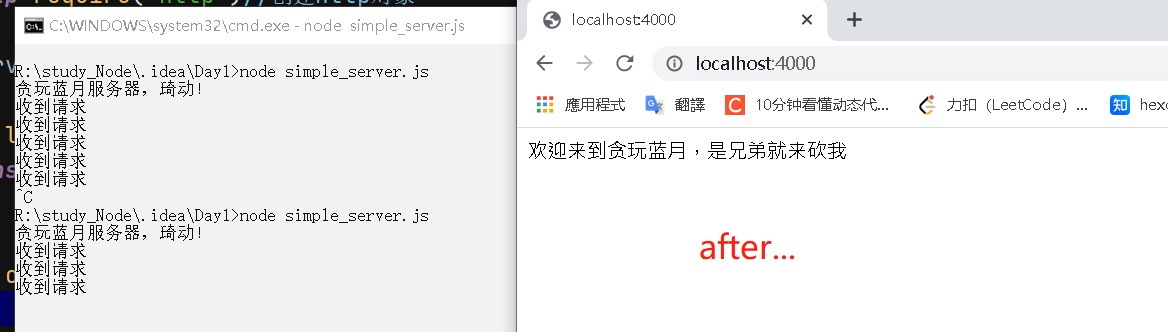
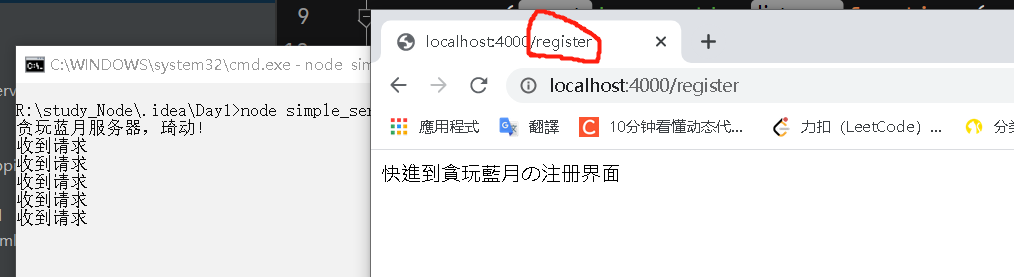
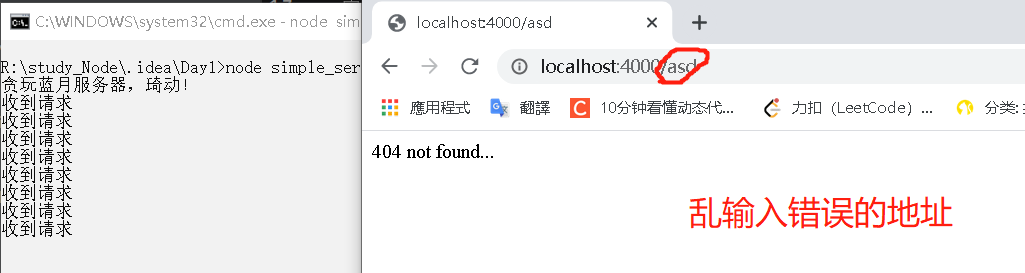
当然一个网站肯定不能只是傻傻地响应同一段内容,服务器必须根据浏览器(客户端)发来的请求信息来对应地响应合适的内容。
实现方法也特别简单,加入一组if-else的判断就可。(详情见上代码line10-21)
实现效果:
And:
2.模块系统
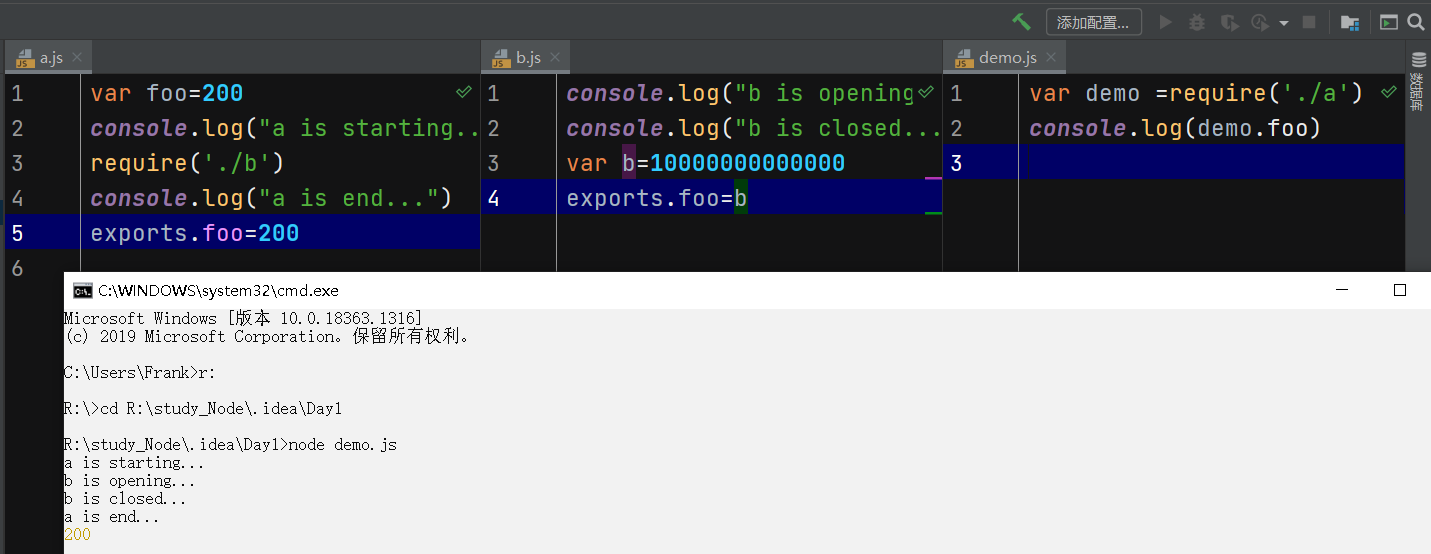
解释:在demo中引入模板a—>执行a的代码,在控制台打印starting语句—>引入模板b—>打印模板b的opening和closed—>a中的引用结束,打印a的end—>打印从a模板获取的值foo=200
从中我们发现输出的foo值是模板a中的,而不是b模板中的。这也体现了模块作用域的好处:可以加载执行多个文件,可以完全避免变量命名而产生的冲突(认真脸)
⑥相关知识补充
同步(Synchronous)
A程序调用B程序,必须等待B程序完成才能返回到A程序,A程序继续执行……从流程上看是一条”直线“
异步(Asynchronous)
A程序调用B程序,此时A不会等待B程序是否执行完毕,而是继续往后执行自己的代码……从流程上看是出现了一条从主线产生的“支线”
回调函数
A callback is a function that is passed as an argument to another function and is executed after its parent function has completed.(来自谷歌的解释)
通俗讲就是
①你到一个商店买东西,刚好你要的东西没有货,于是你在店员那里留下了你的电话,过了几天店里有货了,店员就打了你的电话,然后你接到电话后就到店里去取了货。在这个例子里,你的电话号码就叫回调函数,你把电话留给店员就叫登记回调函数,店里后来有货了叫做触发了回调关联的事件,店员给你打电话叫做调用回调函数,你到店里去取货叫做响应回调事件。回答完毕。
什么还不懂?行,还有个例子:~~②约会结束后你送你女朋友回家,离别时,你肯定会说:“到家了给我发条信息,我很担心你。” 对不,然后你女朋友回家以后还真给你发了条信息。小伙子,你有戏了。其实这就是一个回调的过程。你留了个参数函数(要求女朋友给你发条信息)给你女朋友,然后你女朋友回家,回家的动作是主函数。她必须先回到家以后,主函数执行完了,再执行传进去的函数,然后你就收到一条信息了。~~~(单身的看例子①就好了)
Day2
今天主要围绕模板引擎的概念以及应用方式、渲染这两点展开,并且相对应地结合两个小案例来更进一步的理解感受它们。话不多少,先介绍主要概念。
神么是模板引擎?
模板引擎(这里特指用于Web开发的模板引擎)是为了使用户界面与业务数据(内容)分离而产生的,它可以生成特定格式的文档,用于网站的模板引擎就会生成一个标准的HTML文档。这就好比于我们的写作模板,我们想写什么类型的文章比如说明文,记叙文,抒情文,应用文。它们都有固定的一套模式,我们只要按照这套模式来,往里面添加我们自己的内容即可。
常用模板:art-template(art-template 是一个简约、超快的模板引擎。
它采用作用域预声明的技术来优化模板渲染速度,从而获得接近 JavaScript 极限的运行性能,并且同时支持 NodeJS 和浏览器。)
安装方法:
1 | npm install art-template --save |
啥是渲染?
在电脑绘图中,渲染是指在指用软件从模型生成图像的过程。而在HTML中则是指如何加工并且显示出最终的HTML页面。我们又根据加工场景位置的不同把HTML渲染分为服务端渲染和客户端渲染。
互联网早期,用户使用浏览器浏览的都是一些没有复杂逻辑的、简单的页面,这些页面都是在后端将html拼接好的然后将之返回给前端完整的html文件,浏览器拿到这个html文件之后就可以直接解析展示了,而这也就是所谓的服务器端渲染了。而随着前端页面的复杂性提高,前端就不仅仅是普通的页面展示了,而可能添加了更多功能性的组件,复杂性更大,另外,彼时ajax的兴起,使得业界就开始推崇前后端分离的开发模式,即后端不提供完整的html页面,而是提供一些api使得前端可以获取到json数据,然后前端拿到json数据之后再在前端进行html页面的拼接,然后展示在浏览器上,这就是所谓的客户端渲染了,这样前端就可以专注UI的开发,后端专注于逻辑的开发。
服务端渲染aka后端渲染(service-side render)の优缺点:
- 优点
- 减轻前端压力
- 不用占用前端的资源,比如在用手机浏览网页时,浏览器的负担减轻,因此能够节省手机的电量
- 有利于SEO(Search Engine Optimization)搜索引擎优化。爬虫能够爬取到在后端的HTML文档
- 缺点
- 不利于前后端分离,开发效率低。使用服务器端渲染,则无法进行分工合作,则对于前端复杂度高的项目,不利于项目高效开发。另外,如果是服务器端渲染,则前端一般就是写一个静态html文件,然后后端再修改为模板,这样是非常低效的,并且还常常需要前后端共同完成修改的动作; 或者是前端直接完成html模板,然后交由后端。另外,如果后端改了模板,前端还需要根据改动的模板再调节css,这样使得前后端联调的时间增加。
- 占用服务器端资源。即服务器端完成html模板的解析,如果请求较多,会对服务器造成一定的访问压力。而如果使用前端渲染,就是把这些解析的压力分摊了前端,而这里确实完全交给了一个服务器。
客户端渲染aka前端渲染(client-side render)的优缺点:
艾达王替矩(advantages):
- 前后端分离,前端能够自定义UI而不用去过度依赖后端
diss艾达王替矩:
- 前端的响应速度会变慢,这就是为什么我们在浏览一些网页时,经常会*“爱的魔力转圈圈”*。(后端的渲染速度要比前端的快)
- 不利于SEO。目前比如百度、谷歌的爬虫对于SPA都是不认的,只是记录了一个页面,所以SEO很差。因为服务器端可能没有保存完整的html,而是前端通过js进行dom的拼接,那么爬虫无法爬取信息。 除非搜索引擎的seo可以增加对于JavaScript的爬取能力,这才能保证seo。
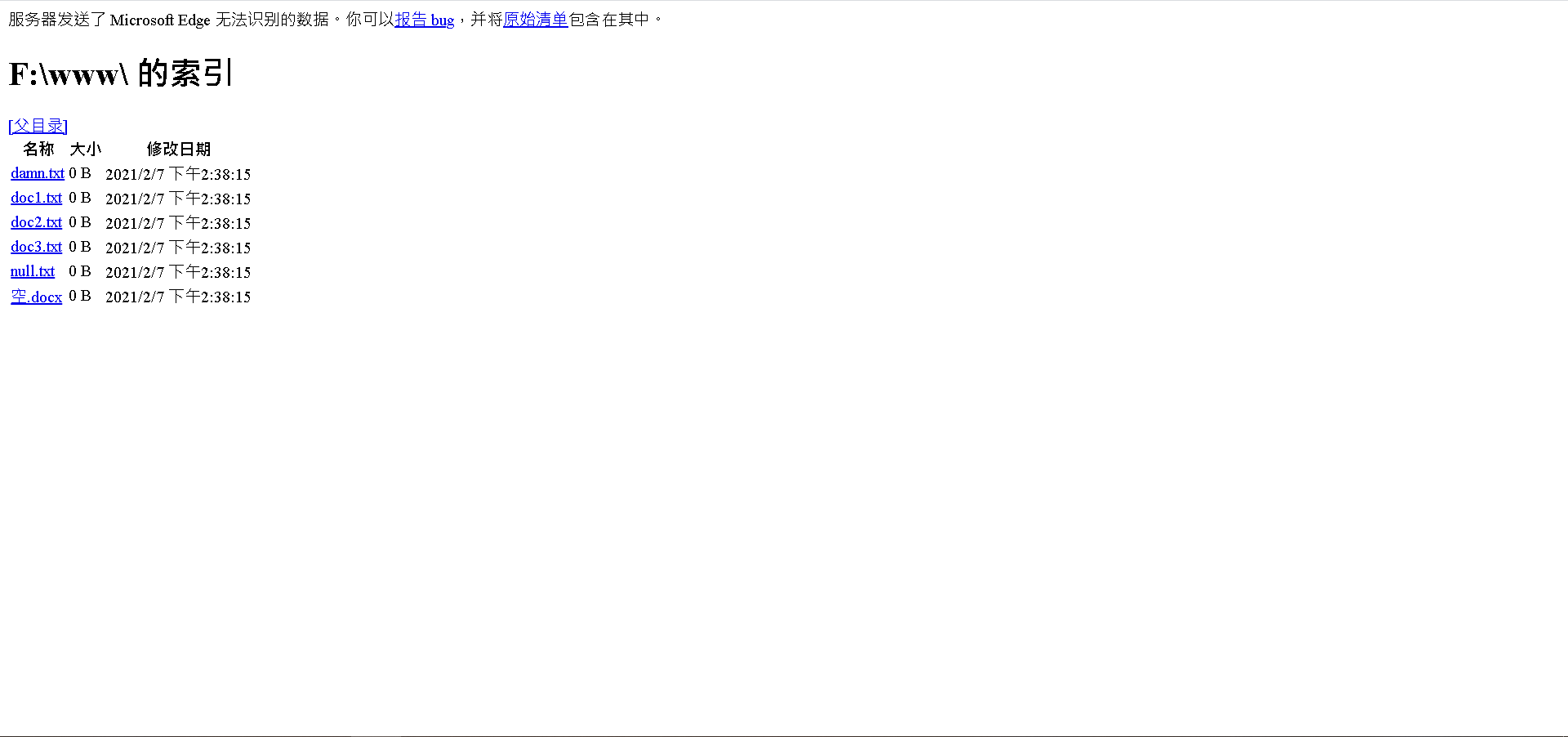
小案例一:模拟Apacheの目录HTML(服务端渲染)
在此之前我们还需要用到fs模块的readFile()和readdir()方法,简单介绍一下这两个方法:
readFile():
能够读取指定路径下的文件并保存到data中,data是一个二进制的数据流(里面全是010101),因此要将其转变为我们认识的字符串需要用到toString()方法。readdir():
读取指定目录下的所有文件夹名,并返回一个由这些文件夹名构成的字符串数组files。
1
2
3
4
5
6
7var fs = require('fs');
fs.readdir('readdirtest', function(err,files){
if(err){
console.log(err);
}
console.log(files);
})
操作描述:
加载必要的模块fs,http…
设置端口号xxxx
为服务器设置响应信息
读取模板文件template.html(目录显示页),并且将要替换的区域使用特殊符号进行标记,这里我使用了***-.-***这个标记
读取目录列表的所有文件夹
并将要替换的部分用一个变量content表示
用forEach方法依次取出files里的文件夹名并构建content(见代码20—24)
将第一步读取的data转换为字符串
简单字符串解析替换操作,将template中替换的区域-.-(特殊标记)用content代替
发送响应
下面是一小段代码:
1 | var fs = require('fs') |
结果截图:
小案例二:art-template
需要一个用于储存模板的html和一个js文件
html模板:
1 |
|
如果没有art-template,运行结果如下:

加了art-template后:
1 | var fs=require('fs') |

由此可见,art-template只关注中的值,不会去关心html中的格式。因此可以理解为***js数据传到html中展示出来***
Day3
Node中的模块系统
模块の定义:
node应用由模块组成,采用的commonjs模块规范。每一个文件就是一个模块,拥有自己独立的作用域,变量,以及方法等,对其他的模块都不可见。CommonJS规范规定,每个模块内部,module变量代表当前模块。这个变量是一个对象,它的exports属性(即module.exports)是对外的接口。加载某个模块,其实是加载该模块的module.exports属性。require方法用于加载模块。
使用Node编写应用程序主要就是在使用:
Ecmascript
核心模块
- 文件操作fs
- http服务的http
- url路径操作的模块
- path路径处理模块
- os操作系统模块
第三方模块
- art-template
- 必须通过npm下载
开发者自个儿写的模块(自定义的)
模块化
文件作用域
通信规则
- 加载require
- 导出
CommonJs模块规范
这就是要谈论的——模 块 系 统
- 模块作用域
- 使用require方法用来加载模块
- 使用exports接口对象来导出模块中的成员
加载require
操作:
1 | var 自定义变量名称=require('模块') |
两个作用:
执行被加载模块中的代码
得到被加载模块中的
exports导出接口对象
导出exports
- Node中是模块作用域,默认文件中所有成员只在当前文件模块有效
- 如果我们想要访问其他模块的成员,可以把这些成员加载到
exports上去
导出多个成员:
1 | exports.demo=foo |
也可以这样导出多个成员:
1 | module.exports={ |
导出单个成员(指定的):
1 | module.exports='666' |
注意:在使用module.exports时,后一个的会覆盖前一个的module.exports
原理
在底层代码中:exports是module.exports的一个引用—>exports=module.exports
1 | console.log(exports===module.exports)//会返回true |
require方法加载规则
核心模块
- 模块名
第三方模块
- 模块名
开发者自己写的
- 路径
优先从缓存加载
- 加载过的模块会暂存入缓存中,若下次还有调用,直接从缓存中读取, 能有效提高模块加载效率
package.json
每一个项目最好有一个包描述文件(package.json,就像产品的说明书)。可通过npm init生成 。有了该文件,再用npm install就能把文件里的依赖项全部下载回来,就相当于原先有了备份,现在进行备份还原
- 在每个项目的根目录下应该有一个package.json文件
- 每次安装第三方包时,应该在后面加上``–save`,可以用来保存依赖项信息
npm
命令行工具
1 | npm install --global npm//更新命令 |
常用命令
npm init -y//快速生成package.json文件1
2
3
- ```shell
npm installnpm install 包名//下载指定包1
2
3
- ```shell
npm install --save 包名//下载指定包并保存到package.json的dependencies中npm uninstall 包名1
2
3
- ```shell
npm help//查看使用帮助npm 命令 --help//查看指定命令的使用帮助npm install --global cnpm//--global表示安装到全局,不能省略。以后就能用cnpm代替npm了1
2
3
4
5
6
- 如何解决npm被墙的问题
- 安装淘宝的cnpm:npm config set registry https://registry.npm.taobao.org//默认使用淘宝服务器下载1
2
3
- 如果不想安装cnpm但是又想用淘宝的服务器下载,可以通过:1
2
3
4
5
## Express
一种Web开发框架
npm install express –save//安装express
1 |
|
静态服务(静态 资源获取)
1 | // 开放静态资源 |
在Express中获取表单请求数据
获取get请求数据:
Express内置了一个api,可以直接通过req.query来获取数据
1 | // 通过requery方法获取用户输入的数据 |
获取post请求数据:
在Express中没有内置获取表单post请求体的api,这里我们需要使用一个第三方包body-parser来获取数据。
安装:
1 | npm install --save body-parser; |
配置:
// 配置解析表单 POST 请求体插件(注意:一定要在 app.use(router) 之前 )
1 | var express = require('express') |
使用:
1 | app.use(function (req, res) { |
在express中配合和使用art-template
安装:
1 | npm install --svae art-template |
配置:
1 | app.engine('html',require('express-art-template'))//第一个参数表示渲染以art结尾的文件 |
使用:
1 | app.get('/',function(req,res){ |
如果希望修改视图渲染的目录(原本是views),可:
1 | app.set('views',目录路径) |
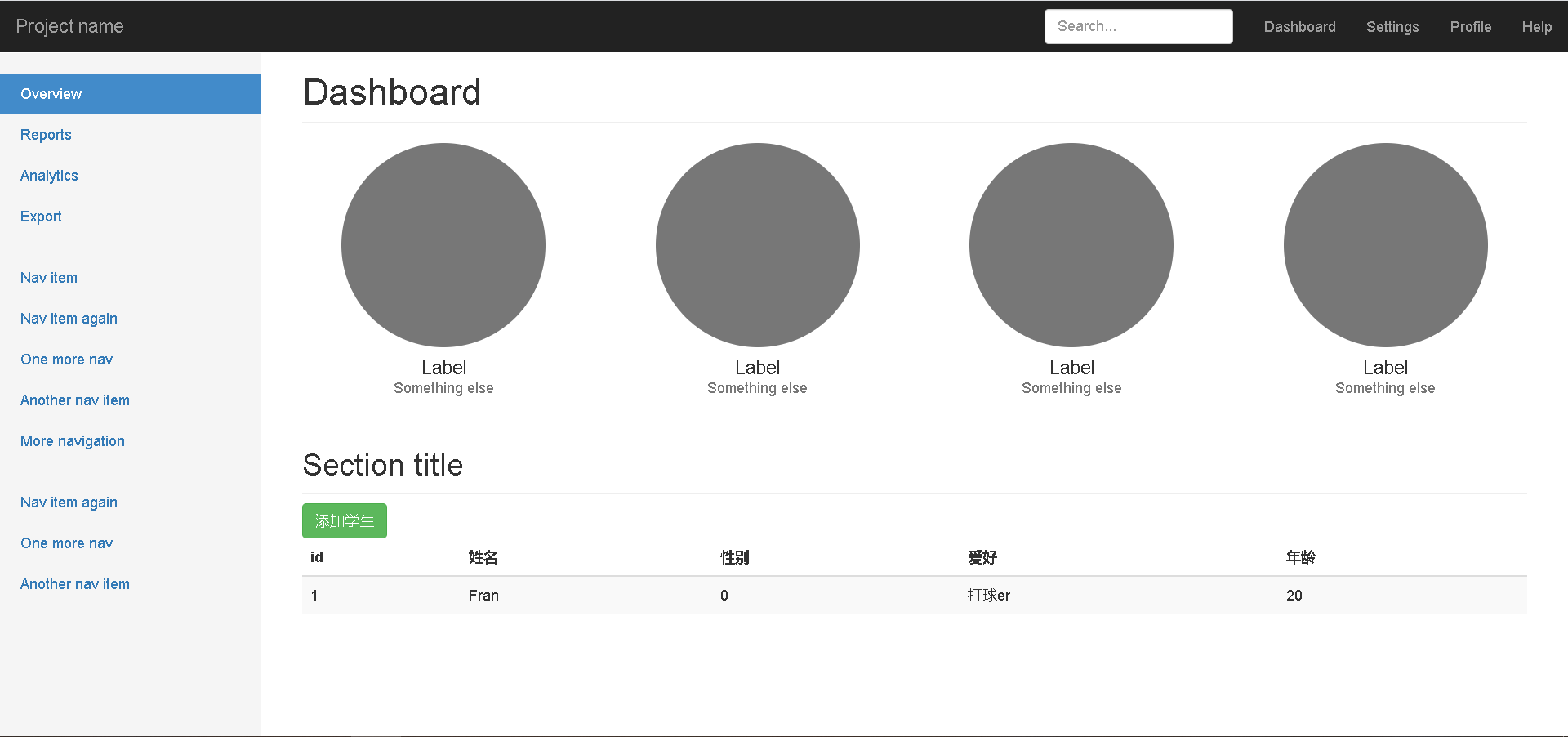
CRUD(待更…)
其他项
①修改完代码自动重启
以前每次修改完代码都要傻乎乎地去node xxx.js现在有了nodemon这一个第三方命令行工具,就能解决这一问题。
安装方法,懂得都懂
1 | npm install nodemon --global |
②封装异步API
回调函数:获取异步操作的结果
1 | function fn(callback){ |
③关于json文件格式の坑
json文件格式要求极其严格,比如
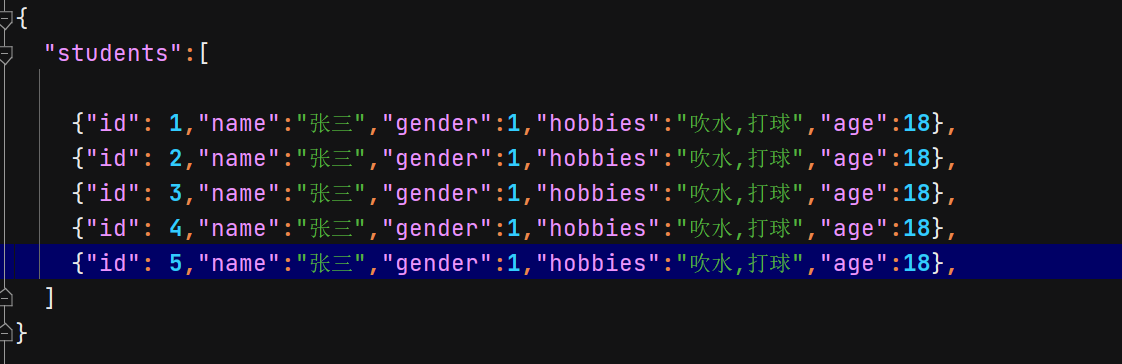
致命错误在:id为5的一行末尾的逗号,一定要去掉!!!***结尾***的一个花括号不能有逗号(就这个错误折磨了我半个小时……)
小项目
一个简单的表单提交网站
路由设计
| 请求方法 | 请求路径 | get参数 | post参数 | 备注 |
|---|---|---|---|---|
| GET | /students | 渲染首页 | ||
| GET | /students/new | 渲染添加学生页面 | ||
| POST | /students/new | name,age,gender,hobbies | 处理添加学生请求 | |
| GET | /students/edit | id | 渲染编辑页面 | |
| POST | /students/edit | id,name,age,gender,hobbies | 处理编辑请求 | |
| GET | /students/delete | id | 处理删除请求 |
提取路由模块
router.js:
1 | /** |
app.js:
1 | var router = require('./router'); |
数据操作文件模块
1 | /** |
成功插入数据の截图:
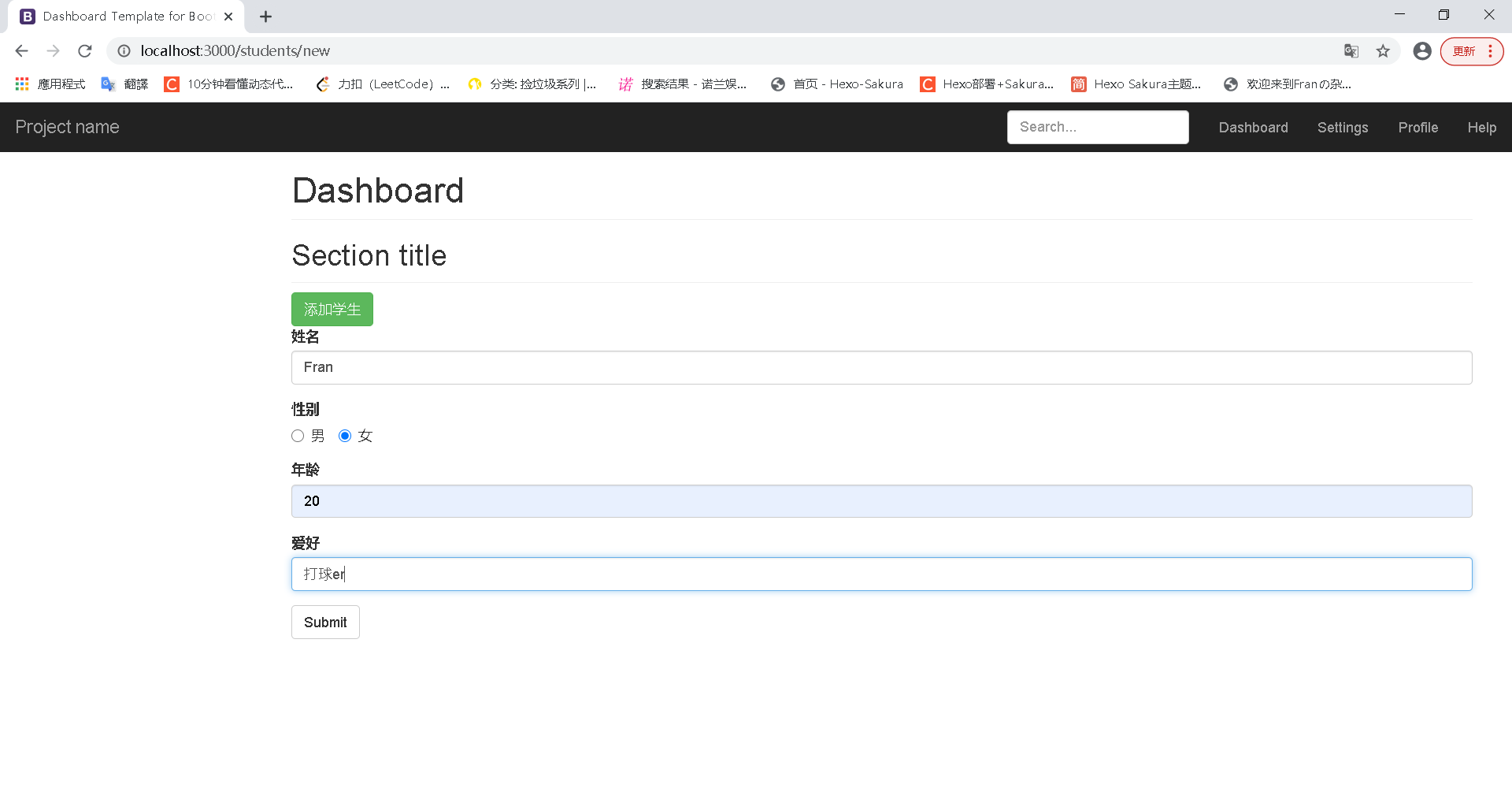
点击submit,成功重定向回主页并渲染完成の截图
小结:
通过这个小项目的练习,可以体会到当进行异步编程时,要想获取异步函数的数据就要使用回调函数
Day???2022.11.25
简单的服务端
1 | require('http').createServer(function (req, res) { |
简单的客户端
1 | require('https').request({ |
了解res和req对象
了解一些常用的API
- writeHead
- end
- on(‘data’, callback)
- on(‘end’, callback)
- on(‘error’, callback)
马赛克网站
服务端
1 | let http = require('http') |
mosaic.html
1 |
|
通过Connect实现一个简单网站
注意:书上的connect版本过低,因此有些写法会有所改变,下面是最新的写法
1 | let connect = require('connect') |
其中serveStatic是一个中间件,中间件(middleware)是一个函数,它本身接收一系列配置,然后返回一个函数,所以最后执行相关操作的是这个被返回的函数
一些中间件
static
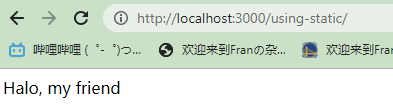
connect允许该中间件能够挂载到url上,允许任意一个url匹配到文件系统的任意一个目录
1 | server.use('/using-static', serveStatic(__dirname + '/website')) |
query
能够获取查询字符串这一部分的数据
body parse
用于获取post请求的数据



